 Jake Runzer
Jake RunzerThe Future of Databases is Services
Welcome to Railway Launch Week 01. The theme of this week is Scale. Throughout the week we’ll be dropping some amazing new features to help your business and applications scale to millions of users.
If this is your first time hearing about us, we’re an infrastructure company that provides instant application deployments to developers.
A long time ago in a galaxy far, far away, Railway started as a place to host Postgres databases.
That’s right, Postgres and nothing else.
When users wanted to deploy different types of databases, we added support for Redis, Mongo, and MySQL. This is what we now call Plugins.
Over the years, Railway evolved to support code deployments from GitHub and the CLI, but we still only supported the same original four databases. When requests poured in to expand our database offerings, it became clear that maintaining custom plugins for each database was not scalable.
You see, the way Plugins are implemented is very custom to each specific database. Adding support for more requires a non-trivial amount of code and the long-term maintenance cost is high.
As long as we held onto Plugins, we were in a jam. We were blocking our users while maintaining an unscalable solution — the worst of both worlds. We needed to unlock a way to deploy ANY type of database on Railway, including new technologies like PGVector, Chroma, Temporal, and more.
We needed to eject Plugins entirely, but with hundreds of thousands of users on the platform, we’d have to rebuild the entire plane while we flew it.
This is the story of how we built Next-Gen Databases.
Here’s where the mess really starts: Plugins and Services are isolated concepts in Railway and are represented in completely different ways in our application, routing, deployment, and networking layers. Each time we added a platform feature, Plugins fell farther behind.
Services are what Plugins should have been from the start. They were designed with flexibility at their core, allowing for the modeling and execution of any type of workload, and allow us to move much more quickly when adding new features.
None of the things that are being announced this week would have been possible if they had to work with plugins too. That’s why features like Private Networking and Regions do not support plugins.
We would have deprecated plugins long ago if it wasn’t for one big problem: You’ve never been able to actually deploy a database as a Railway service.
… Until now.
Databases have slightly different infrastructure requirements than your typical NodeJS or Python webserver. In order to deprecate plugins, we had to add support for everything that a database needs to run in the cloud.
That is exactly what we did.
Over the last few months, we’ve been hard at work filling in the gaps of our platform and building all the necessary primitives to make it possible to host database-like stateful services.
Instead of only making these features available when deploying a database, we’ve released each of these things separately — first to Priority Boarding to be battle-tested, and then to everyone in GA.
Here is a timeline of how these features went out. (If you’re new to Railway, you should know that Priority Boarding is our beta program.)
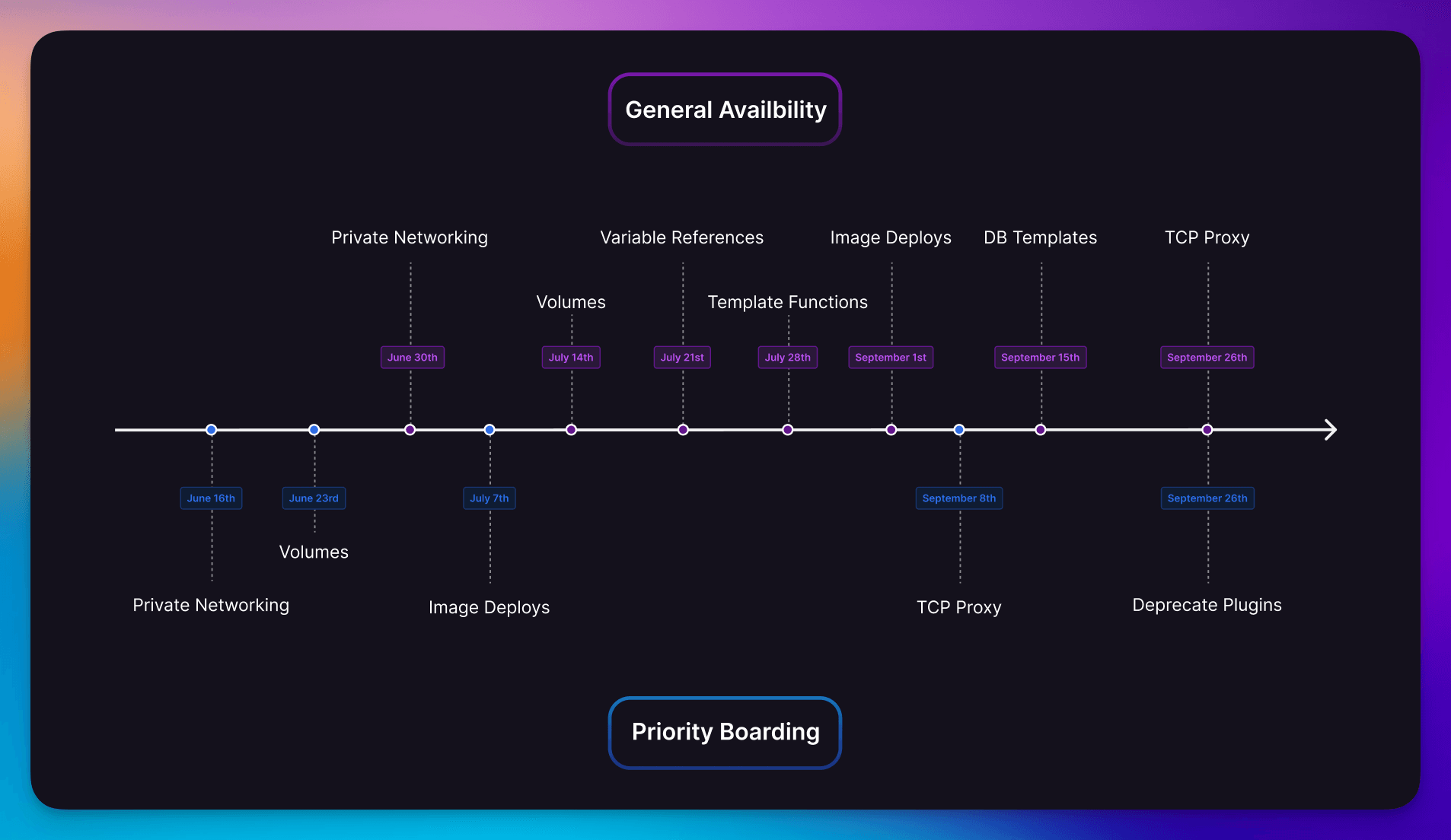
Timeline of all features released to support database services
Now let’s dive into the primitives and how we built them.
One of the most critical aspects to consider when deploying a database is persistence. It is vital to ensure that your data remains secure and intact. However, in Railway deployments, the file system is ephemeral, which means it is not designed for long-term data storage. To address this challenge, we released Volumes, a solution that provides reliable and durable storage for your services.
In true Railway fashion, we wanted to reduce to zero the complexity of deploying volumes. We’re talking as little configuration as possible. You can add a volume to any service and all you need to specify is a mount path, the directory within the container that the volume mounts to. No other configuration is necessary. From within your application you simply need to write to the mounted directory and the data will be persisted. As simple as that. Volumes are even deployed to the region of the service they are mounted to.
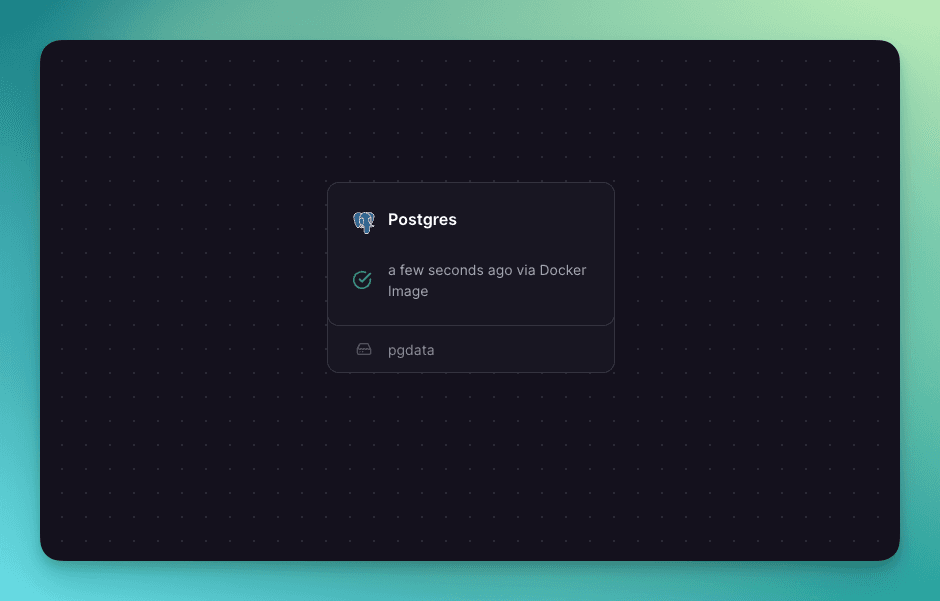
Service with a volume mounted
Railway volumes are built on top of ZFS on fast NVME disks, perfect for database storage.
Up until a few months ago, all you could deploy onto Railway was a directory of files that came either from railway up or from a GitHub repo. Databases are different. You definitely don’t want to have to create a GitHub repo for every Postgres database that you deploy that only contains a single Dockerfile. Deploying the image directly from DockerHub is much much nicer.
This is why we built Docker image deploys. Simply “CMD+K Docker Image” and you are off to the races. We currently support public images from DockerHub and GHCR, but private registry support is on the roadmaps. Supporting any Docker image also means that you can deploy specific versions of database and not be locked in to the ancient version that our plugins use.
Most databases don’t communicate over HTTP. This was a problem for us since we only supported HTTP web traffic through service and custom domains. Our plugins used a completely different way of proxying connections. That containers-us-west-XX domain that you might be familiar with maps to a big list of domains managed by Cloudflare DNS.
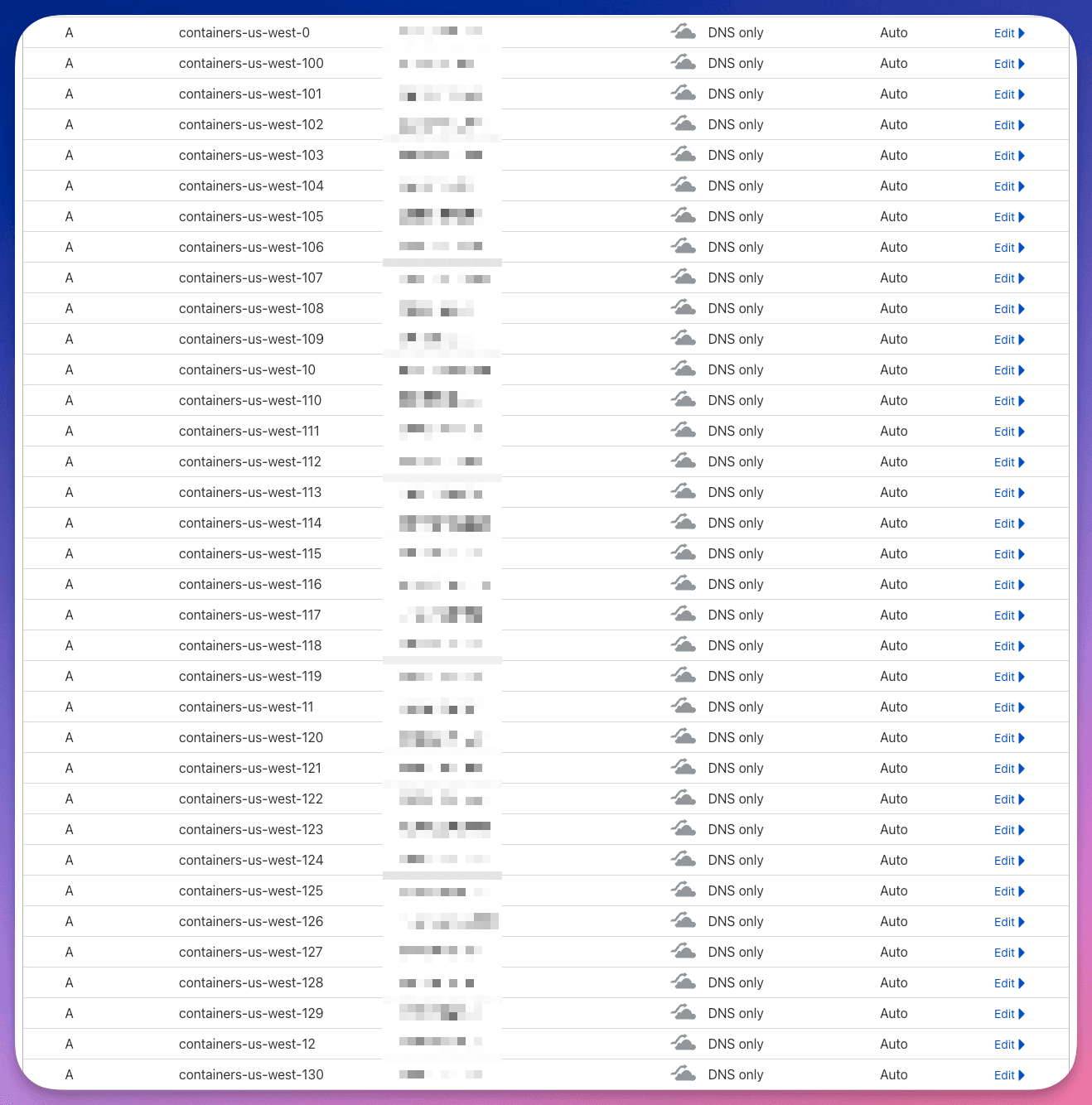
Mess of Cloudflare DNS config for plugins
HTTP traffic is nice because our edge proxies can inspect the Host header of the request and use it to determine which deployment to route the traffic to. With TCP you don’t have that luxury. When a TCP packet arrives, all you can see is the destination port (and some other stuff). To be able to route TCP traffic to the correct deployment, we need to listen on a bunch of different ports, with each port corresponding to a unique service.
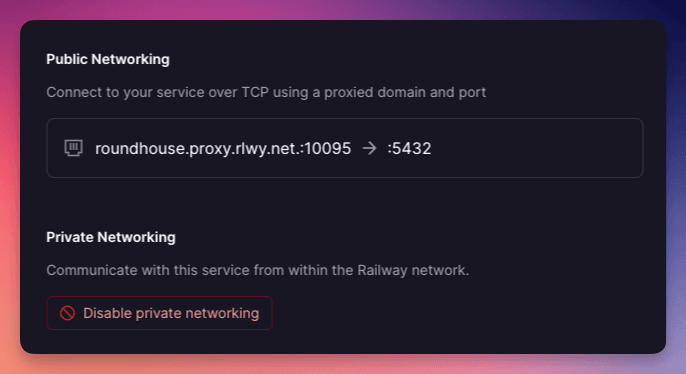
Creating a TCP proxy for a service
Enter the TCP proxy, which does just that. From the service settings page you can now “Create TCP proxy” which gives you a domain and a port. TCP traffic sent to this domain:port pair will be routed to the latest deployment of your service.
Now you can seamlessly connect to your Postgres, Redis, and (insert niche db here) services from anywhere in the world. The TCP proxies are deployed to each region, which means that your database queries will take the shortest route to your database. This is a massive win over plugin databases.
Of course, if you want to privately communicate with your database you can now do that too (see below).
A major problem with our current version of plugins is that they are not part of your project’s private network. This is not great for production applications where security is crucial.
Since the new version of databases is built on top of services, they just sort of … work out of the box with the private network.
Pretty nice if you ask me.
All you have to do is remove any domain or TCP proxy and your database will be inaccessible to the public, yet fully accessible over the secure private network. This setting is also configurable per-environment, so your development database can be accessible over the public network while your production database is locked down.
With plugins, variables were very nuanced.
Initially, we piped in all plugin variables to every service when they deployed. However, this didn’t work if you wanted to deploy multiple databases of the same type. So we changed it so you would need to create variable aliases that reference the plugin (e.g. MY_DATABASE_URL=${{ Postgres.DATABASE_URL }}).
We’ve now extended this functionality to services so that any service can reference another service’s variables (including the Railway provided variables). This means that a service can essentially export data by simply creating a variable. All you have to do is reference the variable to import and use it.
For example, let's look at the DATABASE_URL variable in our official Postgres template.
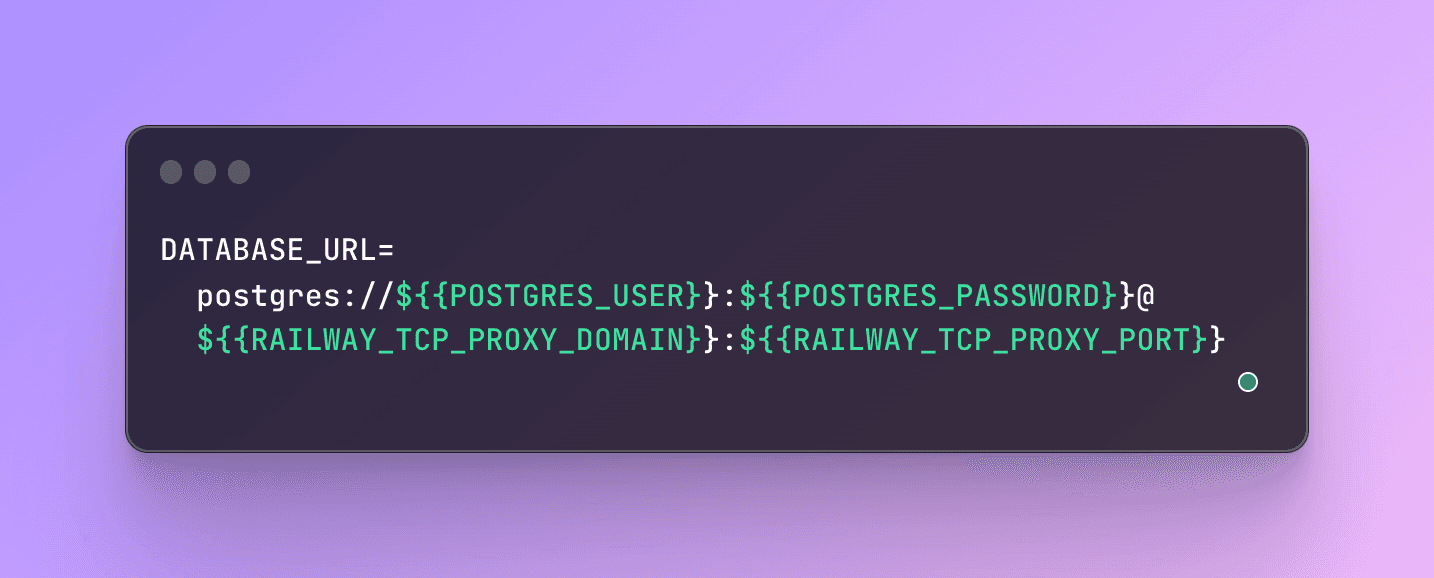
Creating a DATABASE_URL variable using service variable references
You can see it is composed of several variable references. Railway variables can reference other variables within the same service, Railway provided variables (prefixed with RAILWAY_), and variables in other services.
In the variable above, the host and port are provided by the TCP proxy. To use the variable, you simply need to import it.
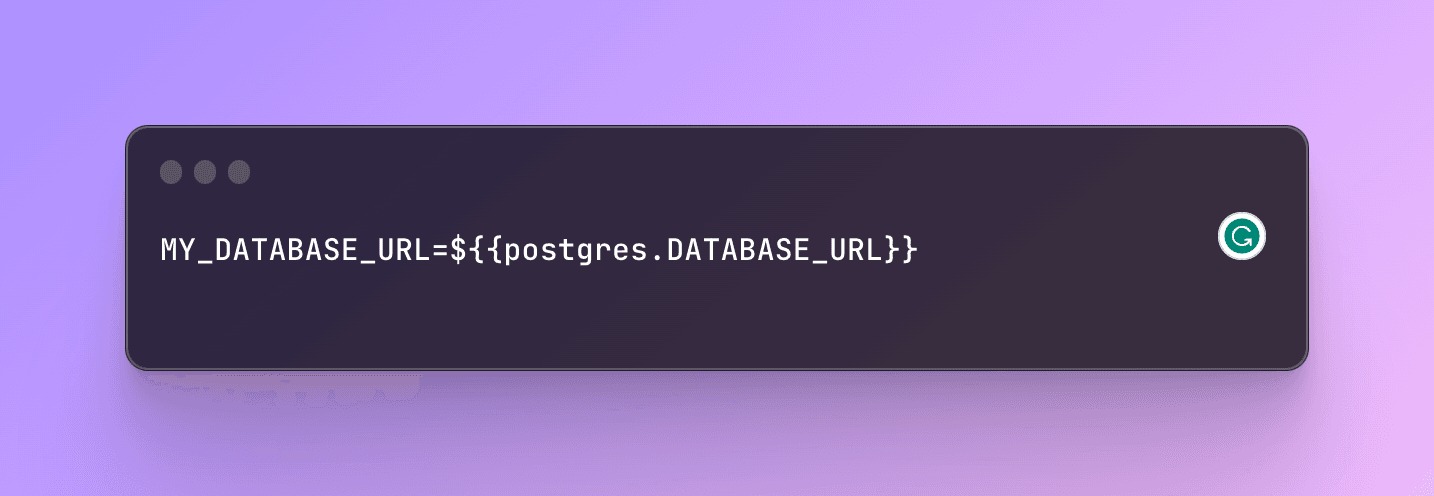
Referencing the DATABASE_URL from another service
This is the exact same functionality that was previously available in plugins, but now it’s generic, composable, and available to everyone.
The last piece of the puzzle was passwords. Plugins on Railway have a custom code path for generating database passwords, where we randomly generate one on creation and save it to the container variables
To enable anyone to create a reusable database, we needed to expose this functionality in a much more user-friendly way.
This is why we built template variable functions. When creating a template, you can set the default value of a variable to ${{ secret() }}. When deployed, this function will be collapsed to a randomly generated secret value. We also support custom secret lengths and alphabets.
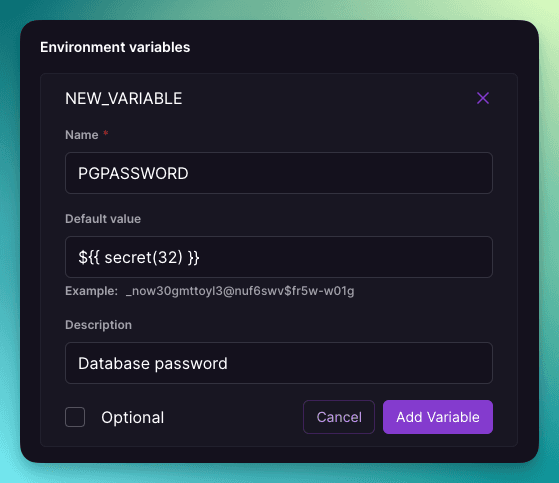
A template variable that will generate a password on deploy
Now that we had all the necessary primitives to deploy databases, we needed a way to save the configuration to something reusable and deployable in one click. This is where templates come in. With a few minor tweaks to the template button composer, you can now specify everything you need to deploy database templates, including a Docker image as the service source, the TCP port to proxy to, and the mount path of a volume.
Put it all together and you get a reusable 1-click deploy database!
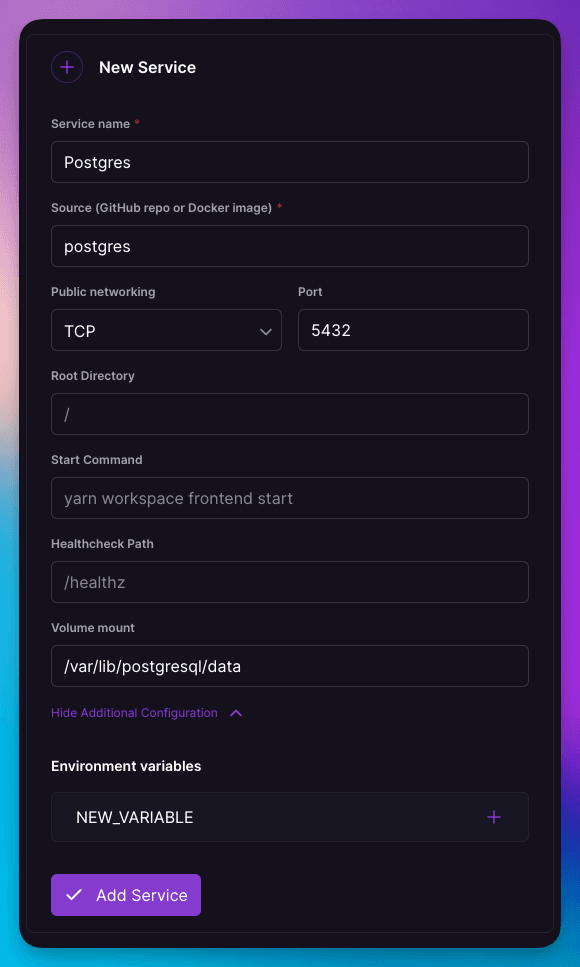
Configuring a template with a volume and TCP proxy
Getting to this point has been a journey, but now Railway is more powerful than ever. When combined, these primitives allow you to deploy any type of database onto the platform. This includes VectorDB, Chroma, SurrealDB, MinIO, ClickHouse, Temporal, and more.
The four original database types have been converted into templates that leverage the aforementioned primitives. But that is not the best part. These primitives also enable everyone to create and share any type of database that can be deployed globally in 1-click. Our plugins UIs will also work seamlessly with deployed database templates in the “Data” tab of the service.
In the future, we plan to add native support for database backups and high availability by following the same pattern: Add the primitives that can be used by anyone.

The master plan for databases is finally coming together
You can try this out today by checking out one of the following templates.
These can be copied, forked, and manipulated in any way you desire. They work like any other service on Railway, with full support for Regions and Private Networking. This unlocks endless possibilities for you to deploy and customize your databases on Railway. And when ready, they can be published to our marketplace for anyone to deploy.

Railway template marketplace
That’s the power of Next-Gen Databases on Railway.
Stay tuned for Day 03 of Launch Week when we’ll be introducing a new way to scale your applications!
Building the infrastructure which powers the Railway engine is the most core problem at Railway. Reach out if you’re interested in joining the team.
