 Angelo Saraceno
Angelo SaracenoHow We’re Building Git for Infrastructure
Welcome to Railway Launch Week 01. The theme of this week is Scale. Throughout the week we’ll be dropping some amazing new features to help your business and applications scale to millions of users.
If this is your first time hearing about us, we’re an infrastructure company that provides instant application deployments to developers.
What if you could take your projects from 1 → n just like you would with Git? What worlds would it open for your development workflow if your infrastructure on Railway was fully versioned and reproducible?
Well today that’s possible with Changesets, our first major Lifecycle Management release.
Let’s get into a technical breakdown of how we made this happen.
If you were going to ship a simple application without Railway, you’d likely make a Docker image, throw it up on a VM, and get it started.
If you wanted to persist that setup, you’d likely use a CI or config-as-code tool to track and make reproducible changes to the deployment.
That’s all fine and dandy when you’re toiling away on your project solo. However, when you introduce a team of engineers into the mix, these operating procedures start to gum-up the works … that’s when you’d normally need to go in and start racking up loans with everyone’s favorite financial instrument: Tech Debt.
Railway innovated on the no-questions-asked, multi-language deployment experience. However, when it came to working together as a team on Railway, companies told us about the messy middle. They would struggle with adding settings, triggering new deployments, and then having to wait around to see if those changes worked. And if you wanted two people to change the settings at the same time? Forget about it.
Changing configuration could be so much better without the need to fight over merge conflicts in a TF file. (We felt this too since we use Railway at Railway.)
That’s when we got to work on Changesets.
When spring was in full swing, we dived into the hero’s developer’s journey on our platform.
We started thinking about infrastructure in the context of a version control system. When you develop application code, you create branches, test things out in different environments, and then merge those changes together before shipping them into production.
As you’re undergoing this process, you incorporate feedback from your team and your customers and you evolve an idea of what production means to your product. It’s a fact finding and discovery mission as your product grows.
Infrastructure development should feel no different. To us, it should feel like pottery — you throw some clay on the lathe, fix those errors as they come up, and try again.
For example, let’s say we start using Redis to cache some data. Shouldn’t we be able to add Redis to our infra stack in an environment, develop and test in that environment, and then merge that change into production?
With Changesets we’re making it easy to fork and merge environments with the click of a button. It’s now easy to create new environments, test changes in those environments, and merge those changes into production.
In developing this feature, the trick for us was to hide the complexity from view while making the benefits clear and obvious. Instead of wrangling a bunch of files and having to reason about application and config changes, diffs are now a first-class citizen within the Railway console.
Versioning infra environments isn’t something new in the industry, but at Railway we’re focused on making it as simple as possible, because that’s how we do things.
With all due respect to YAML, all you need to do on Railway is create a new environment and then select the parent environment to inherit from.
Forking an environment and staging changes in action
Changes made in the new environment don’t affect other existing environments. Each environment is like a git branch, and every change made in the environment is like a git commit.
When it’s time to bring a changeset into production, the changeset may be consolidated into the parent environment by clicking the "merge" button.
As a result of merging a changeset, all changes that have been made to services and/or environment variables are now effectively versioned — nice!
Let’s get into how we built this feature and where we’ll be taking it.
To implement Changesets, our team took inspiration from Git.
Originally, we thought this might also work under the hood in a way similar to Git — every commit would have a parent commit which would allow us to query the history of changes in an environment, every environment would point to its HEAD changeset, and so on.
The engineering team then discussed how to make queries fast and performant while staying within the constraints of our relational database. But this architecture would have quickly killed performance. We’d have to query one record at a time, get its parent id, query another record … pretty expensive and the Tech Debt credit card has a low limit.
Our second idea was to query in-project changesets and build the tree in-memory. We would then discard changesets that weren’t relevant to the action e.g. if they belonged to another environment. This would have been fast in most cases, but it might also be very memory-intensive since in some circumstances it would require multiple queries of the history.
So the second idea was better than the first, but still not ideal.
Just like in Git, where a commit can belong to multiple branches, in Railway, a changeset can belong to multiple environments if they share history. So we knew we needed to avoid making a Changeset belong to a single environment.
The best solution turned out to be treating changesets as having one (and only one) "original" environment.
Let’s take a look at why.
gitGraph
commit id: "A"
commit id: "B"
branch staging
commit id: "C"
commit id: "D"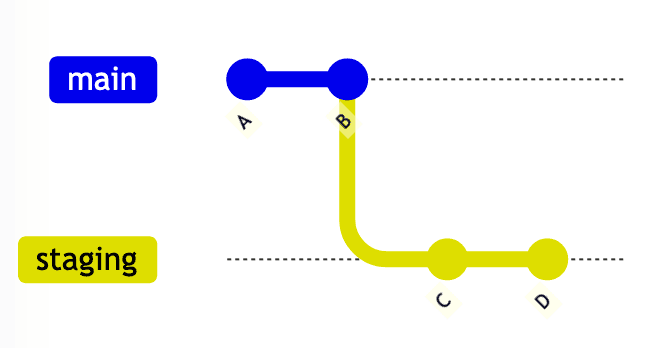
In a typical Git Graph like this, every commit belongs to a branch. The team realized that we could implement the concept this way and make it efficient provided we stored the parent environment of each environment.
For example, let’s say we have two environments, `A` and `B`, and `B` was forked from `A` starting from changeset `X`. To find the diff between both environments, we would simply need to query each changeset in `A` that is newer than `X`.
To timestamp each changeset, we implemented an internal id for each changeset that’s stored in a PostgreSQL serial column. With this unique id, we can sort without having to compute any hash like in Git.
The database guarantees ordering and integrity of the data while also giving us the ability to register atomic changes in the form of database transactions.
One thought we had during the design phase was, Do we need to also introduce the concept of pull/migration/deploy requests? After all, this would allow users to merge arbitrary environments between each other. We eventually discarded this idea.
Since we want to make things as easy as possible, we distilled the feature to the most common use case, which is forking an environment and merging it into its parent environment. We reasoned that if we could let you pull or merge changes from/into the parent environment, this would work for 99.99% of use cases. This lead us to believe that it simply wasn’t worth making the vast majority of use cases more complicated to make 0.01% of use cases easier.
Our data model makes also these use cases super simple to solve. Since we store the timestamp and parent environment of each changeset, we just do a simple query to compute the diff.
Sometimes the simplest solution is best.
There’s a whole other blog post to be written about how the team diagramed the logical flow with Mermaid and Git Graphs, and how we have a DSL to test the system.
Wait, this is that blog post!
Adding fork and merge to environments required a number of changes to a number of parts of our codebase. We needed to test cases with a crazy number of permutations of varying types.
When we started writing tests, we noticed that the tests were hard to reason about. Very quickly it became impossible to determine things like lineage across environments.
Then we had a revelation. Since we’d used Mermaid and Git Graphs to describe how our implementation would work in an internal RFC, could we make our tests just as easy to reason about?
In Mermaid we had something like this:
gitGraph
commit id: "A"
commit id: "B"
branch staging
commit id: "C"
commit id: "D"
branch develop
commit id: "E"
commit id: "F"
checkout main
commit id: "G"
commit id: "H"
checkout staging
commit id: "I"
commit id: "J"
merge develop
checkout main
merge stagingWe then wrote a test helper class with methods very similar to the commands found in Mermaid. An example of these tests is as follows:
it("Runs a full workflow with 3 environemnts", async () => {
const t = await FlowTester.init();
await t.changeset("A");
await t.changeset("B");
await t.expectHistory(["B", "A"]);
await t.fork("staging");
await t.changeset("C");
await t.changeset("D");
await t.expectHistory(["D", "C", "B", "A"]);
await t.fork("develop");
await t.changeset("E");
await t.changeset("F");
await t.expectHistory(["F", "E", "D", "C", "B", "A"]);
await t.checkout("main");
await t.changeset("G");
await t.changeset("H");
await t.expectHistory(["H", "G", "B", "A"]);
await t.checkout("staging");
await t.changeset("I");
await t.changeset("J");
await t.expectHistory(["J", "I", "D", "C", "B", "A"]);
await t.expectDiff("develop", ["F", "E"]);
await t.merge("develop");
await t.expectDiff("develop", []);
await t.expectHistory(["F", "E", "J", "I", "D", "C", "B", "A"]);
await t.checkout("main");
await t.expectDiff("staging", ["F", "E", "J", "I", "D", "C"]);
await t.merge("staging");
await t.expectDiff("staging", []);
await t.expectHistory(["F", "E", "J", "I", "D", "C", "H", "G", "B", "A"]);
await t.checkout("staging");
await t.expectDiff("main", ["H", "G"]);
await t.checkout("develop");
await t.expectDiff("staging", ["J", "I"]);
});This was better but we still needed a clearer way to visualize what was going on. Once again Mermaid came to the rescue! We wrote a simple utility function that allows us to output a Mermaid description of the test.
console.log(t.toMermaid());Now when we copy and paste the output in mermaid.live, we can visualize the test. We can do so anywhere in the test, as many times as we like.
This made debugging the feature much easier and let us dramatically shorten the time to implementation.
We now have in production thousands of forked environments and we love hearing from our customers about this much-improved workflow.
Changesets is a monumental feature for the platform. When Railway first came out, we only had ~15 options for configuration, but over time as we added new config options, tracking those changes became more and more tedious.
When we shipped PR environments, we knew that we wanted tighter integration with Git. Product Engineer JR shipped Config as Code and the native nixpacks.toml integration, but something never felt right about evolving your infra on the platform until now.
We’ve been excited to support teams as they coordinate releases and statefully manage configuration as a team. For the future, we want to make Railway’s Config as Code and Changesets fully versionable. Imagine being able to roll back to exact versions of your project and deploy everything in an ordered manner defined within the Railway project — wouldn’t that be great?
We’re off to a great start. We’ve tracked millions of diffs across tens of thousands of environments and the engineering team is gearing up for orders of magnitude more.
Changesets is the continuation of a number of features we’re rolling out in the category of Lifecycle Management. While it was fun to take inspiration from Git and then evolve our design to support the core use cases, we now have a powerful data model which will help us ship new features in the coming weeks and months.
We have companies who have been using this feature in production after our private beta period and we’re now getting calls for RBAC to stage changes and generally overhaul the rollout of deployments. That’s going to take us a bit of time — but this feature, like many others, came from your feedback.
We hope you stay vocal on what we can improve.
Thanks for being along for the ride.
Stay tuned for the final Day 05 of Launch Week when we’ll be introducing something that will change how you see the platform entirely. I know, big, right?
