 Charith Amarasinghe
Charith AmarasingheHello, World: We’re Railway
Welcome to Railway Launch Week 01. The theme of this week is Scale. Throughout the week we’ll be dropping some amazing new features to help your business and applications scale to millions of users.
If this is your first time hearing about us, we’re an infrastructure company that provides instant application deployments to developers.
Hello! 🇺🇸
Welkom! 🇳🇱
Lai liao! 🇸🇬
Today we’re lighting up three new regions: US-East, EU-West, and Southeast Asia. Including our primary availability zone of US-West, we can now say that the sun never sets on Railway.
That’s the big headline for Day 1 of Launch Week: We’re expanding across the planet, with plans to open many more regions in the near future.
The rest of this story is about the Superfund Site known as our Terraform stack, the challenge of plumbing packets across continents, and our dealings with the loans department at the only remaining solvent bank in Silicon Valley: The Bank of Tech Debt.
We’ll get into that in just a sec, but first, we want to show you what we’ve built.
Regions on Railway is 1-click
Did you catch that demo? Changing regions is now as simple as ... changing the region. If it sounds simple, well, it’s not. It’s really, really not.
Let’s jump into it.
Since we started this train in 2020, Railway has operated out of a single GCP availability zone based in The Dalles, Oregon. We’re primarily hosted in the datacenter near the Columbia River, and as sure as that river does flow, so do our grievances with GCP’s service-level offerings (and our fear that a flood might wash away our company).

We’re big fans of GCP as you might be able to tell
While the single-cloud, single-region paradigm has worked for a couple years now, we’ve been laser-focused on expanding scalability, improving reliability, and reducing latency.
Since Regions is the most popular feedback request we’ve ever received, it’s been on our radar for a long while. The most voted requests were for a site in Europe, a site in Singapore, and another site in the US, so that’s what we’re launching today.
So now, onto all the fun nerd shit. That’s what you came for right?
To deliver multi-region at Railway, we needed to build an architecture that gave us flexibility and set us up for success. We’re not just trying to scale across regions within a single cloud provider, but also across clouds (and of course eventually to bare metal, to your private cloud, to an overclocked toaster … basically to anything that can run a binary). For you, the user, this complexity is hidden. Compute is just a commodity we manage and your apps need not care.
These were our initial requirements:
- Regions should be 1-click! That’s The Railway Way™ of doing things — it should “just work” with no ifs, ands, or buts
- Services should be able to move seamlessly between regions without any changes to URLs or DNS records
- Databases should be transferrable across regions, ideally with near-zero downtime
All systems age with time, the best we can hope for in our corner of Startupland is that our solutions last 12-18 months and that we can ship quickly. Regions would be no different but, when we started digging into this back in January 2023, we realized we were missing a bunch of critical prerequisites:
- Private Networking was needed to provide a way of talking between your multi-region services directly, securely, and scalably
- Edge Networks were needed to go global to meet our “No DNS changes to cross regions” goal
- Storage needed to be split from Compute for databases, aka we needed Volumes
- TCP Proxies were needed to shim traffic between an arbitrary DNS name and your moveable stateful service
Because of this, Regions had more pre-requisites than expected. Here’s how we started chipping away at them, starting with Private Networking.
Private networking was a huge feature request and a rather tricky problem for us to solve. We noodled on a bunch of ideas ranging from exotic to very-hacky™️. We explored Linux light-weight-tunnels, VXLAN/Geneve, sidecar proxies, overlay networks like Cilium, and even hacky solutions like iptables + GCP networking.
We knew we wanted Regions and we knew we wanted Private Networking — two projects with many “unknown unknowns” and we didn’t want to paint ourselves into a corner. If we had embarked on Regions first, we’d have a sucky service-to-service networking story and require a potentially hazardous retrofit to a private networking scheme when we eventually came up with one. We needed to make a Private Networking brick so we could build Regions out of LEGO.
Private Networking eventually took the form of a Wireguard Mesh with eBPF based NAT atop it. At Railway, we have a list of technologies we’re betting long on and eBPF is one of those. Each of our compute hosts are part of a large WireGuard mesh network — as long as the host has IP reachability—wherever in the world it is—it can join this Mesh by authenticating with our service discovery system. Wireguard tunnels are low overhead and don’t require persistent connections like other VPNs, so this scales well.
To add the Private in “Private Networking,” we use eBPF to mangle and translate packets. When packets traverse mesh endpoints or the container’s railnet0 network device, they pass through our tiny eBPF programs, which do the following:
- Modify IP packets so we translate between your dedicated
/64IPv6 private network address-space and our backbone network - Firewall each endpoint to ensure only traffic on your own private network can enter/exit your containers
- Hijack DNS lookups and direct them to our internal DNS server
eBPF grants us a level of programability in the network stack that would otherwise be impossible — it’s really powerful and crazy performant. Some of these ideas are extensions of IPv6 Identifier Locator Addressing and our friends at Fly are doing something similar with their own Private Networking setup.
tl;dr: IPv6 + Wireguard + eBPF = future of networking wrapped in pure awesomeness.
We get away with this all mostly at the IP layer. There’s a bunch of places in the network stack that expect L2 to work, so we hack around that with static neighbor table entries to get around having to implement IPv6 NDP.
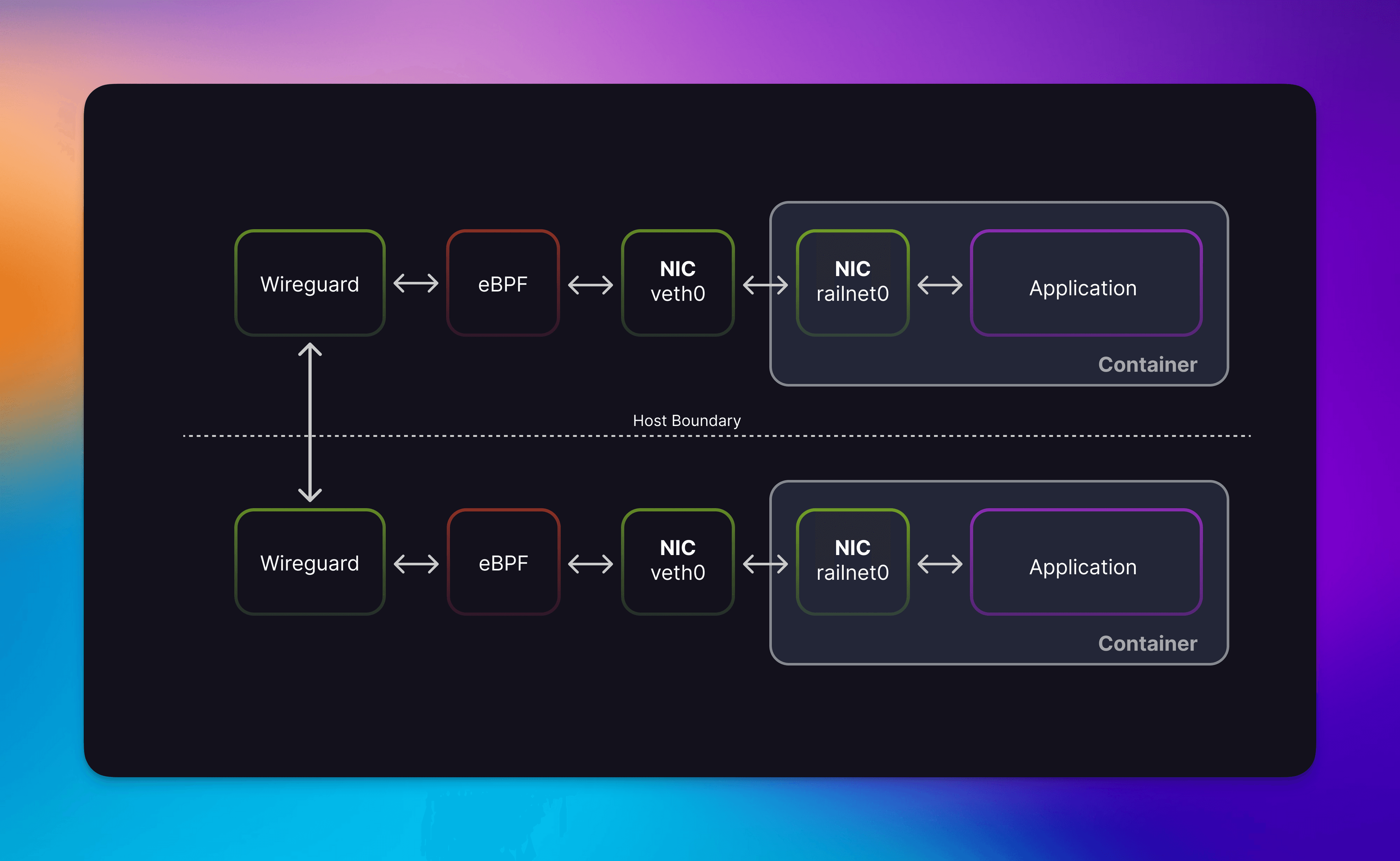
Private Networking: The story of how we managed to get some C merged into our monorepo
The Cilium project has laid a lot of groundwork for what a pure eBPF data plane can look like. In short: conntrack, egress-NAT, and IPIP tunneling in pure eBPF is within the realm of possibility. These are all directions in which we’ll be doubling down as Railway evolves. We’ve got a lot of crazy ideas in this space, from visualizing traffic flows on the canvas to auto-detecting socket binds inside of containers. Wouldn’t IPv4 private networking be super cool to build with 4in6 tunnels constructed with eBPF? [Shameless hiring plug incoming] Why not join us and find out?
With private networking mostly sorted, lets get to public (aka ingress, aka edge) networking. When you create a custom domain or service domain on Railway, your traffic flows from those domains to your apps via our edge network. The edge network is a fleet of Envoy proxies controlled by our custom-built network control plane. Historically, we operated a single fleet of proxy nodes in the US and attached these to the up.railway.app domain. Those proxies terminated TLS and HTTP2 connections before forwarding HTTP requests directly to your app.

Our initial edge network — simple and effective but inflexible
Scaling these globally presented a bunch of problems. We needed edge termination globally but your apps could be in a different region or spanning multiple regions, and we’d need to load balance requests accordingly. If your app happened to span regions, each regional edge termination needed to prefer its local replicas over any global replicas.
We solved this with a two-fold solution that involved splitting the edge terminations from last-leg request routing and building an interconnected mesh of these proxies across regions. To get traffic into this contraption, the replicated edge proxies are placed behind GeoDNS so that resolvers resolve to the IPs geographically closest to them.
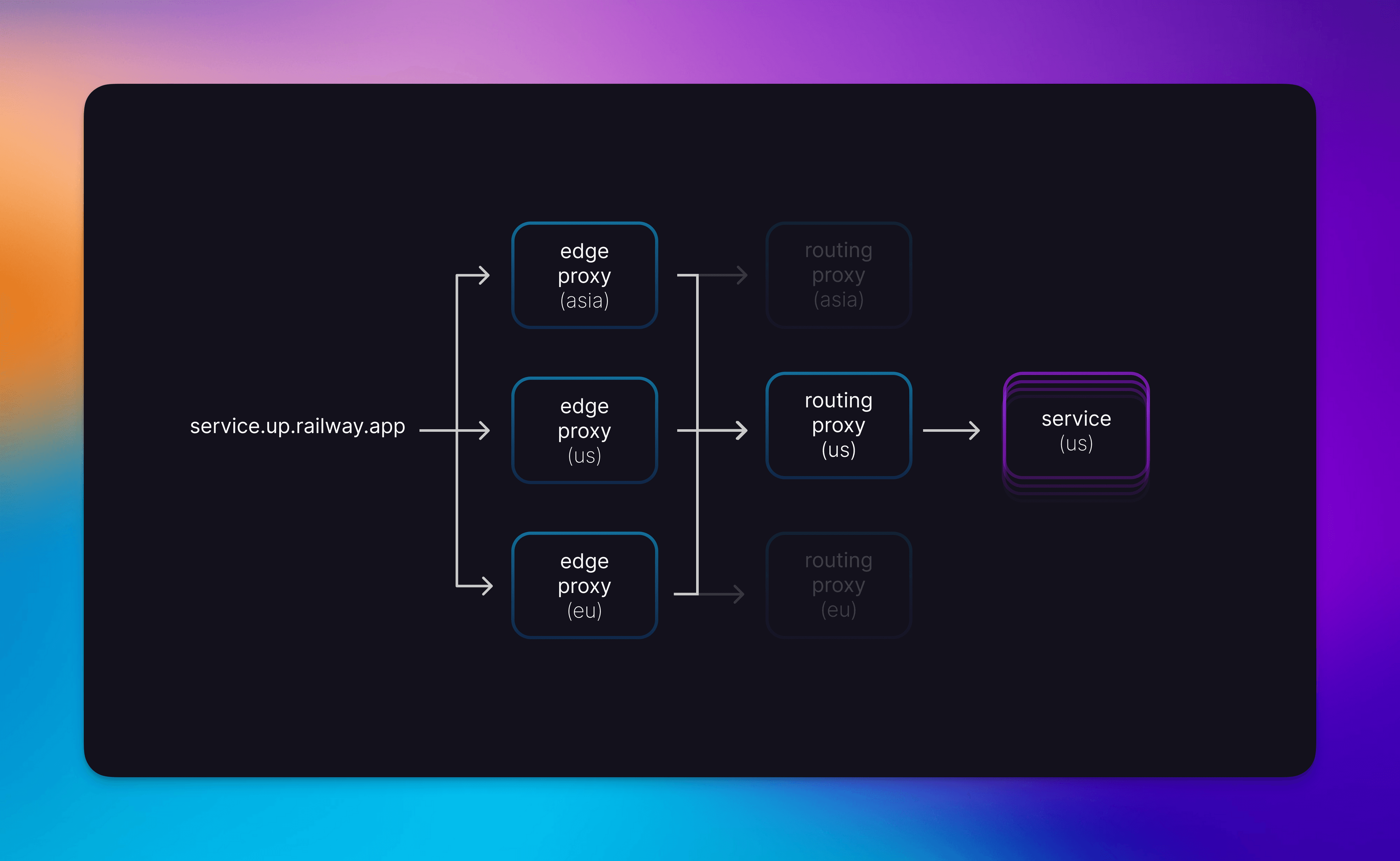
Edge Proxies do regional routing and Routing Proxies route to hosts and load-balance within a region
We like to think of our Edge-to-Routing proxy connections as trunk lines. These TCP connections are pooled and re-used across multiple HTTP requests. This means that we’ve got less connection overhead to worry about when hopping between regions. The only cost here is a few milliseconds extra for DNS resolution of a CNAME record and a few more milliseconds to transit through the new proxy layer (Envoy is fast!).
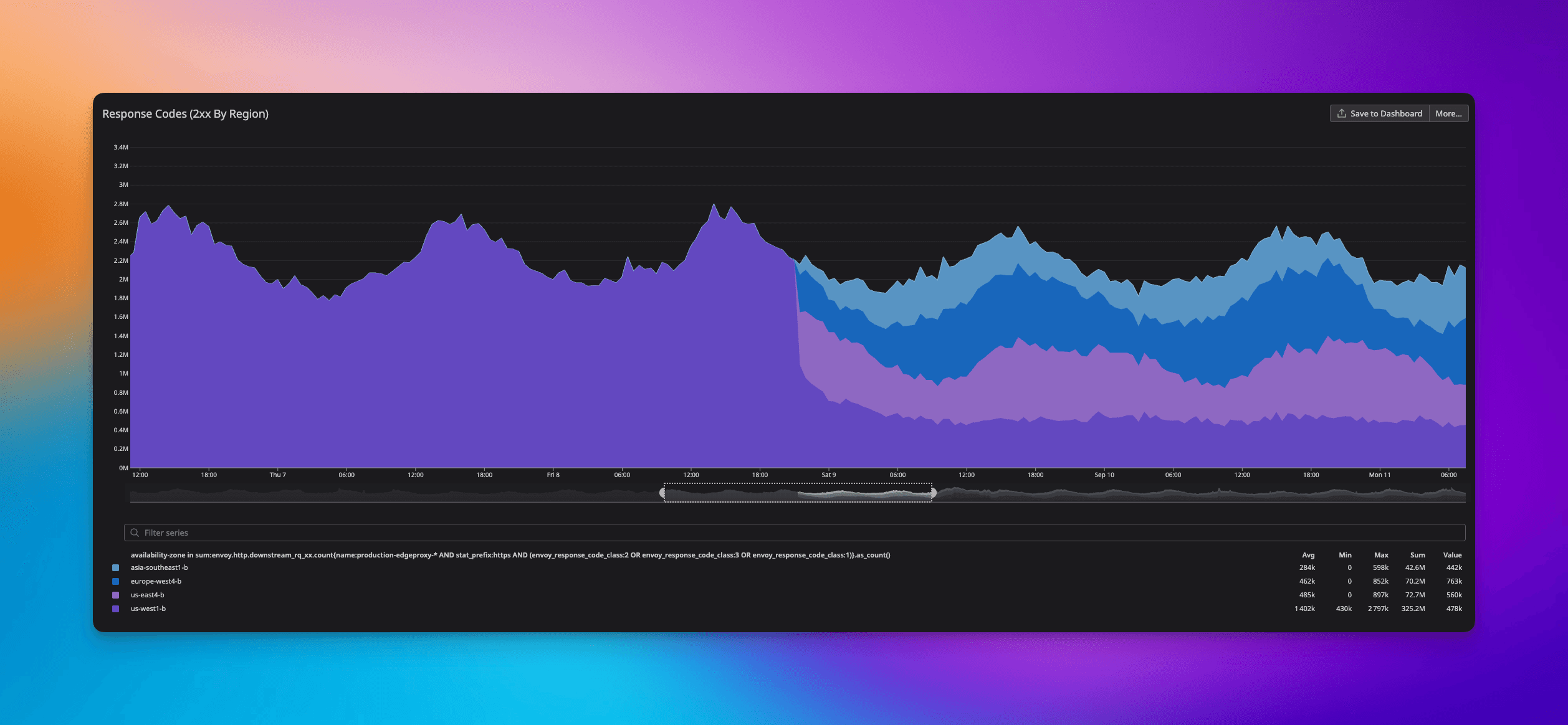
Cutting traffic to the global edge was a beauty to behold. Did you even notice we did that? Hopefully not 😅!
We love Envoy and, although we’ve had some friction with it, we’ve hugely appreciated its insane performance. However, our main issue at present is that each proxy needs a complete copy of our routing config. Updates can be streamed via delta-xDS, but on startup each envoy clones a few hundred megabytes of config over gRPC.
Envoy seems to be evolving in the direction of on-demand versions of their discovery protocols (where config will be pulled lazily), but we’ll have to wait until then. We serve hundreds of thousands of domains (even more routes) and the rate at which these grow gives us some nervousness regarding the mileage we can get. So that’s why we chose a different path for TCP proxying.
Recall how we said we wanted Databases to be moveable across regions? Database wire protocols aren’t always using standard protocols like HTTP, so we need to be able to get arbitrary TCP traffic into a container — a capability we didn’t have previously. At Railway, we like to test out our crazy ideas on narrowly scoped problems and let Darwinian theory decide if those ideas will stick. L4 proxying is possible with Envoy, but we wanted to test our designs for lazy loaded routing configs, building out a testbed for a potential v3 of our HTTP edge.
When you create a TCP proxy on Railway, we assign you a port allocation and DNS name from a pool of free addresses. When you establish a connection to this address, that connection (via GeoDNS) will land on one of our regional TCP proxy nodes. These proxies will do a dynamic lookup on our control plane for the endpoints for that service, cache the result, then load-balance between the returned endpoints. So the initial request to a proxy may take up to a hundred milliseconds to resolve due to the lookup, but subsequent lookups will be immediate due to the cache.
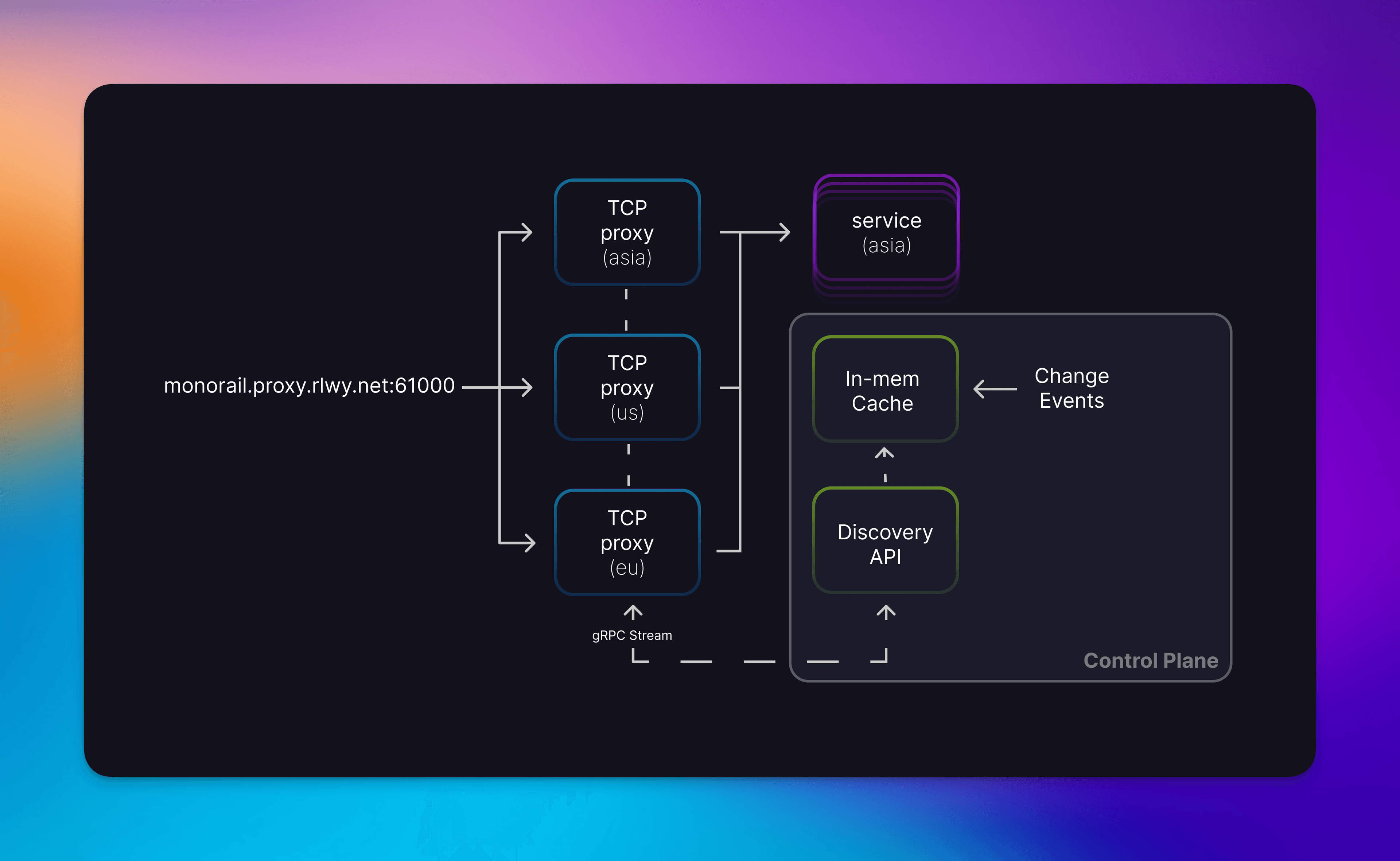
Our lazy proxies only care about the routes they serve while 4-tuple LB’ing gives us some cache locality
How do we invalidate this cache? The fun thing is that the lookup is also a subscription — so any changes to those endpoints (e.g. a deployment) will trigger an invalidation event to be broadcast to every subscribing proxy. This is all possible thanks to an in-memory cache we’ve built on top of memdb, a library from HashiCorp based on immutable Radix trees.
This allows us to build multiple indexed views of our routing table that we can efficiently watch from a clients via a gRPC stream - change events from the rest of our systems (deployments, Service mutations, etc…) will trigger mutations to this in-memory cache. These in-turn cascade to the subscribed watches and via our Discovery API to subscribed proxies.
It may sound like a Rube Goldberg machine patched together with duct-tape, but that’s often how projects start at Railway. We’ll eventually polish it to the point of becoming the room-temperature semiconductor of proxying but, for the moment, it gets the job done and we’ll iterate until it’s great.
Now that getting TCP traffic to your databases is covered, the next piece of the regions puzzle was storing and migrating data between regions.
The biggest advantage we get from deploying on GCP is robust network-based block storage. GCP persistent disk is reliable, built atop GCPs erasure-coded network storage, and backed up frequently for disaster recovery. Plugins store their data on these GCP network disks on top of an Ext4 file system. Though on the road ahead we might consider a custom block storage solution based on Ceph or something custom atop usrblk or vhost-usr-blk, for Regions we decided to solve this at the filesystem layer to support data transfers between hosts.
If we wanted to transfer a filesystem from one host to another, we’d have two options: we could tarball all your files and copy them over to the new host, or we could snapshot the underlying block device and transfer that snapshot.
The latter solution had a big advantage. By building on top of a copy-on-write storage system, a volume transfer could be separated into an online transfer of an initial snapshot and an offline transfer of an incremental snapshot that would capture any writes that happened during the first transfer. This would allow for much lower downtime during transfers, since the volume would need to be unmounted only at the end.
We explored both LVM/devicemapper and ZFS to enable this capability, and eventually settled on ZFS. zfs-send and zfs-receive allow us to smoothly transfer across ZFS snapshots from one host to another, and we wrapped this in a light transport wrapper and orchestrated it inside a Temporal workflow to make it robust and idempotent. Copy-on-Write + Snapshots are also a powerful primitive that will allow us to support fun features like point-in-time recovery at some point in the future.
With volumes out of the way, we finally have the pieces to build out our Regions train. We just had to banish some skeletons that were hiding in our closet. Cue the ghostbusters theme song.
Let’s talk about historical missteps and loan repayments on tech debt.
We operate multiple fleets of VMs on GCP with differing responsibilities. Each of these is bootstrapped via Ansible and the whole zoo is defined in one large Terraform stack. The latter had — wait for it — zero modules. We used the “Photocopier Method” for IaC, i.e. copypasta everywhere. Since Regions should not be more of that, we set about reorganizing our Ansible and Terraform IaC in a way that made sense.
Each service directory inside our monorepo now contains a standardized directory structure. ansible/ contains Ansible tasks, terraform/{{ env }} directories contain terraform stacks and all re-usable modules are vendored into terraform/modules. Some configs span multiple services, we factor these all into a root .common directory. Anything dynamically generated at runtime goes into a .gen directory that is git-ignored.
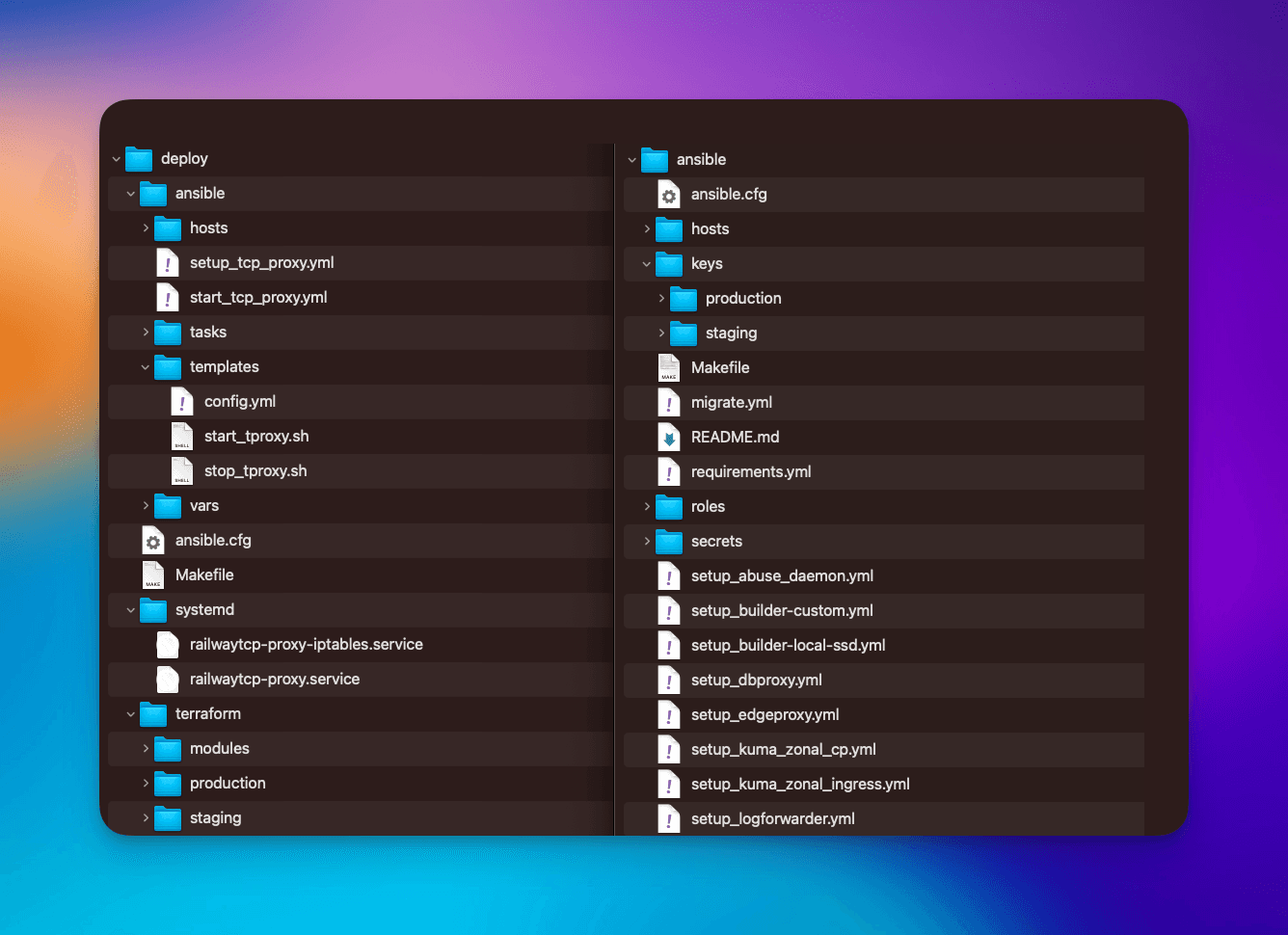
New on the left, old on the right — turns out using directories makes sense after all!
Our Ansible inventory would previously be fetched from a static hosts file. We would manually update that file whenever IP addresses or hostnames changed. We got this wrong multiple times, with hilarious results (one time a build node decided to become a compute node because an IP got recycled — took us a while to figure that one out).
We now generate inventory using the GCP dynamic inventory plugin. This is quite handy because you can pull variables into the inventory from instance metadata. This provides us a path for smuggling config from Terraform into Ansible with zero manual steps. This all works nicely with SOPS too, so all this can live safely in Git.
There are more war stories here, like why our stackers (our internal name for compute hosts) would talk to GCP and Cloudflare in their service discovery loop or why there’s a picture of a Dementor and multiple cobwebs against the words “Service Mesh” in our internal infrastructure map, but these are tales for another blogpost.

Screenshot from our Marauders Map of Railway’s Infrastructure: The creature in the middle is a Dementor. He haunts our service mesh. Nice guy otherwise tho.
So we’ve crafted ourselves some new bricks and solved our weeding problems, what next?
Before we can ship your code, we first need to build it. At Railway, we’re long on Temporal. We use it for everything from billing to building docker images. Our internal, non-Kubernetes orchestrator is built on top of it. With Regions, the target region determines which fleet of builders we’ll use and which fleet of compute nodes we’ll elect for your deployment. These choices then propagate to our network control plane to wire-up the resulting containers to your domains or TCP proxy allocations.
Queues on temporal are cheap, so we give each build node its own queue and join them in a hash-ring to balance builds based on resource usage. With Regions, these queues are now namespaced by their home region and, on each deployment, we route that job to a build node that matches. If you have a volume attached to your deployment, we’ll trigger a job on the associated stacker to transfer your data to a newly elected host in your target region before we kick off that deployment.
Deployments operate similarly to builds: each stacker running compute advertises not just its current mem/CPU/iops/etc to the network, but also its capabilities.
When we create a deployment, we sample the network until we have sufficient information to determine a placement. And then we deploy! All of this happens subsecond.
This functionality allows us to roll-out features to subsets of hosts by adding new capabilities and constraints. This is a powerful tool for development as it allows us to test out risky features incrementally. Private networking was the first to exploit this capability when we rolled it out from a single host to hundreds across the fleet in the course of two weeks. We implemented regions as another one of these constraints.
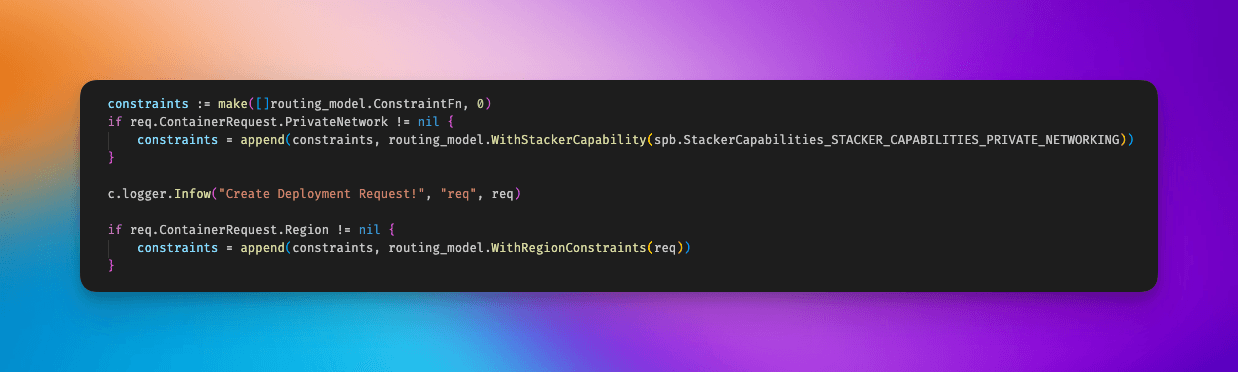
Scheduling constraints are now just an append away
All this comes together to make regions a simple drop-down menu in your service settings. This menu is populated lazily, meaning new regions will be appended automatically as they are added.

Single dropdown: no peering connections, no inter-region transit gateways, no DNS changes
So, what did all this work buy us? More importantly, what did it buy YOU?
We handle everything from builds, deploys, routing and cleanup — seamlessly. When you want to change the region, just go back to the dropdown. We’ll change the underlying region, cut over traffic with zero downtime, and remove the deploy in the old region.
”But, what about stateful services?”
Remember how we spoke about Volumes as a pre-requisites to regions? When you switch the region on a service with an attached volume, we’ll use that tech to replicate your data between regions, verify its integrity, and switch over traffic/writes!
While this happens, builds for that service will be queued and applied once the migration has been completed successfully. (Thank you Temporal!) Pretty cool right?
Our work to launch Regions opens the door to some BIG things on the horizon. The Lego blocks we’ve made are more like Duplo in our minds and we’ll refine them until we’ve got you that shiny Mindstorms set.
On networking, this means doubling down on our eBPF/Wireguard solution to make it the transit for all traffic! Your containers can listen on any number of ports and we can support things like custom protocols. We’ll also expand your options for proxying. We’re toying with ideas for SNI proxying and support for PROXY protocols to allow you to run your own edge on Railway — and spoiler alert — once we do that, we’ll shift our own L7 proxies to be built atop those L4 proxies we’re giving you.
We like the gardens we’re building to have zero walls.
Similarly, we’re going to be delving deeper into the topic of programmable storage — it’s one of our big goals for 2024 and there’s a lot of exciting work on the Kernel that we’re aiming to build on top of. We do volume migrations with near-zero downtime, but near-zero is still not zero. We have ideas for pushing the envelope here by controlling write-synchronization and traffic cutover to migrate databases seamlessly.
Our plans for world domination expansion aren’t done yet. Most obviously, we’re planning for MORE regions but even more exciting are the following scenarios:
- Hosting Railway on our own different clouds
- Hosting Railway on our own baremetal hardware
- Hosting Railway on YOUR clouds/hardware
We’re moving to a world where compute becomes a commodity and Railway becomes your universal self-wiring deployment platform that works anywhere. In the future we’ll be dropping our cookie-cutter Stacker blocks on clouds all over the world and having them show up in the UI as just another region.
If you can curl | sh a binary onto it, you should be able to run Railway on it!
We’re looking forward to that.
So with all that said, here is something we’ve been waiting to say for quite a while:
Hello World, we’re Railway and we’re happy to meet you, wherever you are in the world.
Let’s light ‘em up!
Stay tuned for Day 2 of Launch Week when we’ll be introducing a dramatic expansion of DB capabilities on the platform!
Building the infrastructure which powers the Railway engine is the most core problem at Railway. Reach out if you’re interested in joining the team.
