 Pierre Borckmans
Pierre BorckmansSo You Think You Can Scale?
Welcome to Railway Launch Week 01. The theme of this week is Scale. Throughout the week we’ll be dropping some amazing new features to help your business and applications scale to millions of users.
If this is your first time hearing about us, we’re an infrastructure company that provides instant application deployments to developers.
Remember that time your web server got flooded with requests and said, "I can't even?"
Artistic representation of the Railway of yesteryear
That’s because of the fundamental limitations of vertical scaling.
Everybody likes it when their app is popular, but being overwhelmed with a massive influx of requests is also a frustrating and stressful experience, to say the least.
Up to this point on Railway you would’ve had to roll up your sleeves and take care of it the hard way, with DIY service replication and load balancing. That meant manually replicating services and running your own logic for load balancing:
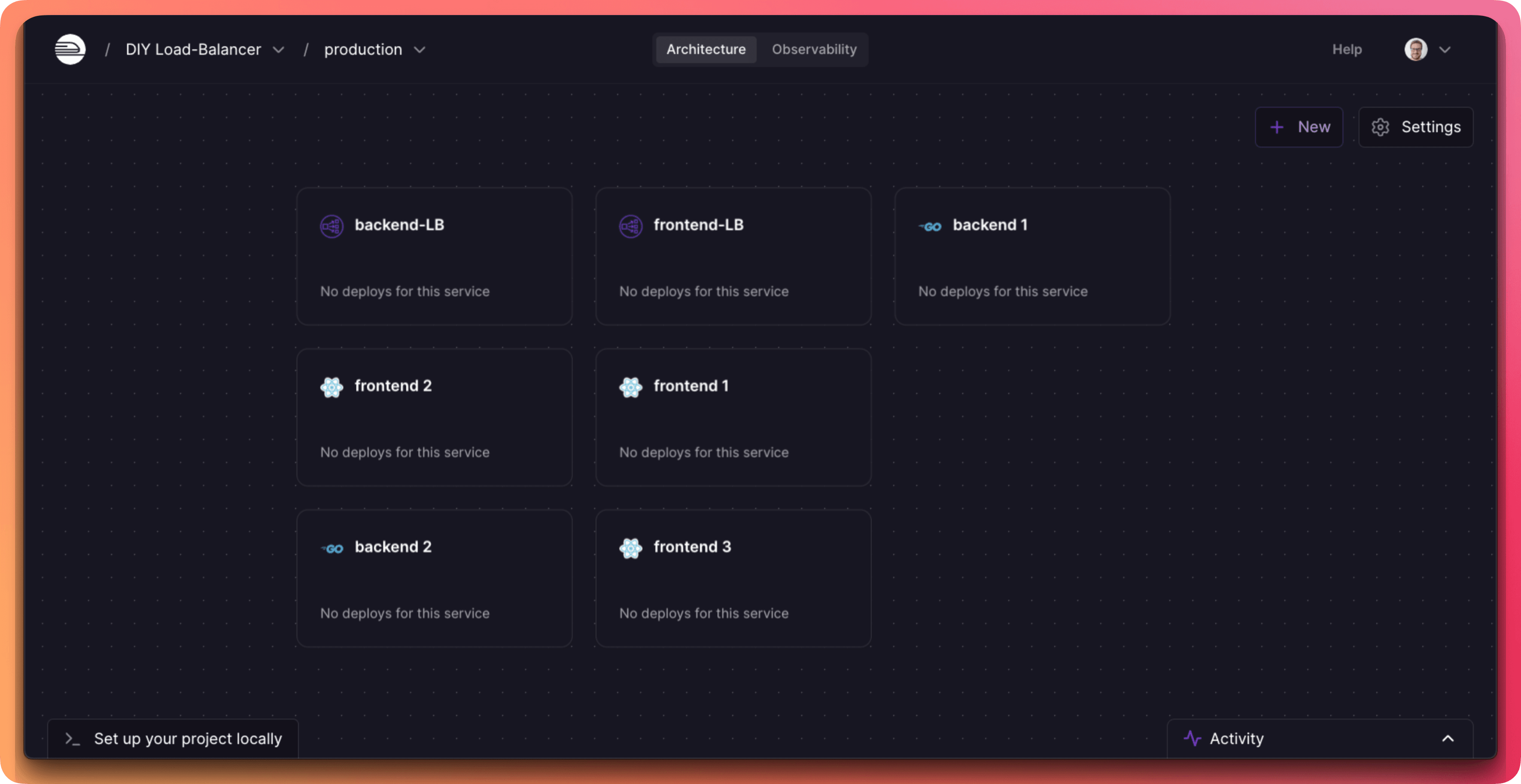
It’s a wonderful thing, the work you no longer have to do
Well, we have good news.
As of today, you can now horizontally scale services on Railway with a single dial!
In this post we’ll get into how that dial works and all the amazing stuff it unlocks as you scale.
With just one setting, you can now choose the number of replicas for each of your services.
Slide that dial to the right to scale up and to the left to scale down.
No fuss, no complex configurations.
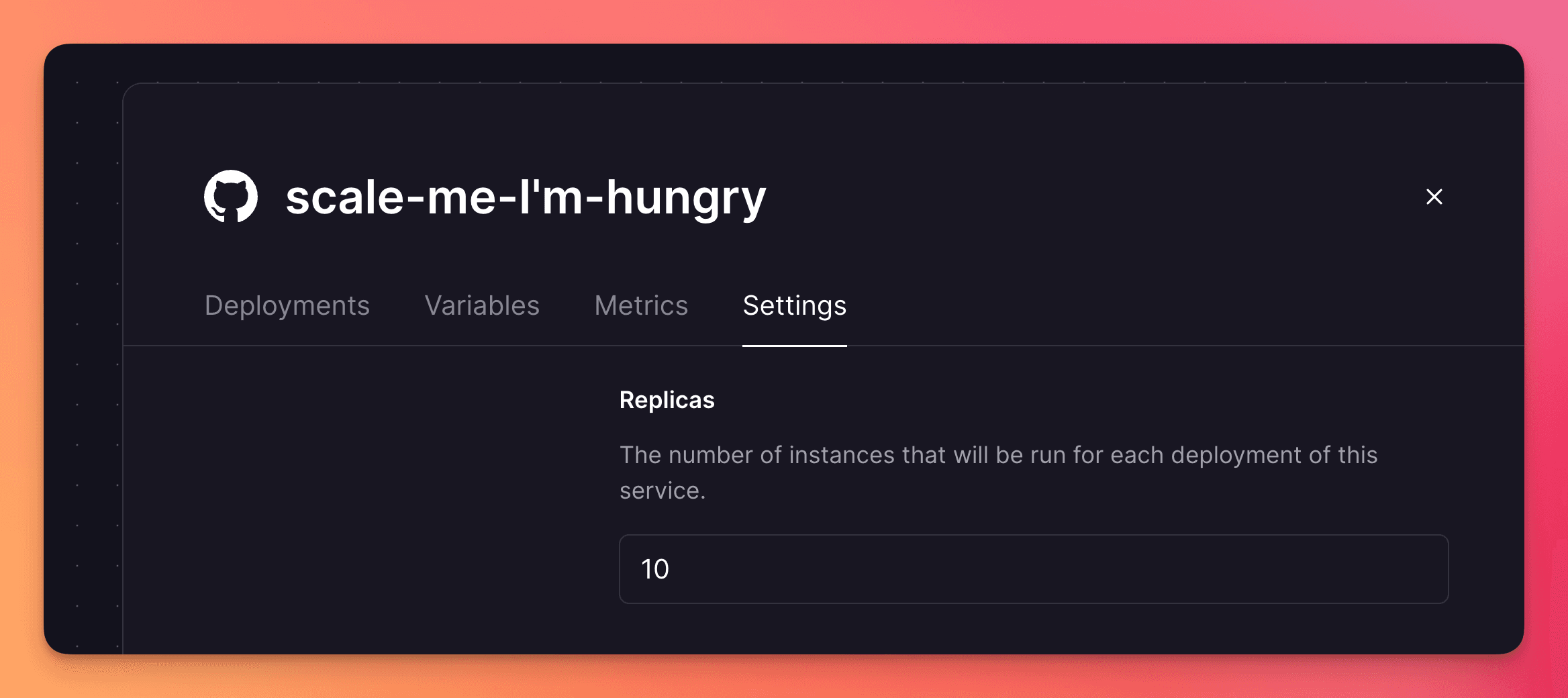
Isn’t this better? We think so.
But replicating containers is the easy part.
The interesting stuff lies in the networking. We knew we wanted to offer you a seamless experience when scaling your deployments: your replicated services should be able to talk to each other, both publicly and privately, with no code change on your side.
That’s why we baked automatic load balancing into the horizontal scaling feature, over both public and private networks.
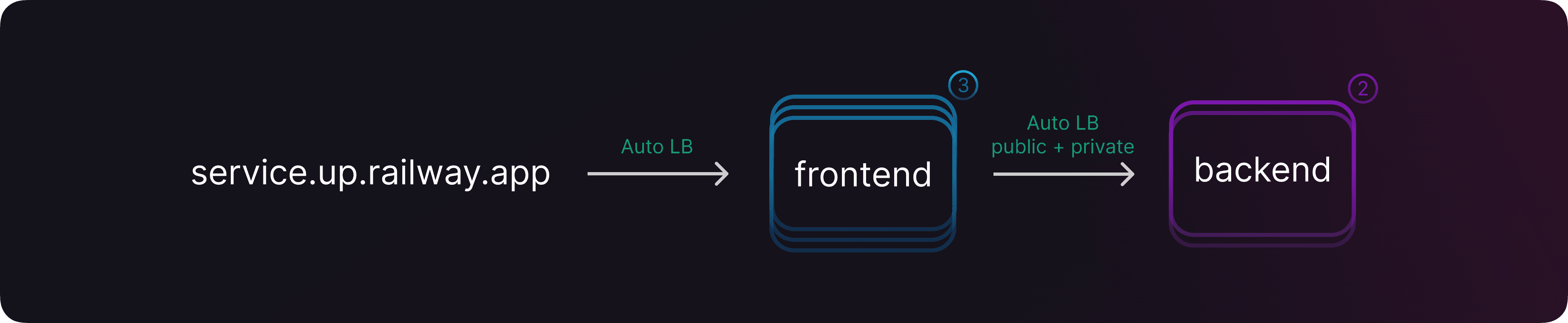
Automatic load balancing is now available
Scaling your deployments comes with another benefit: fault tolerance. Should one of your replicas crash or behave erratically, no worries! Our network will failover to another replica automatically.
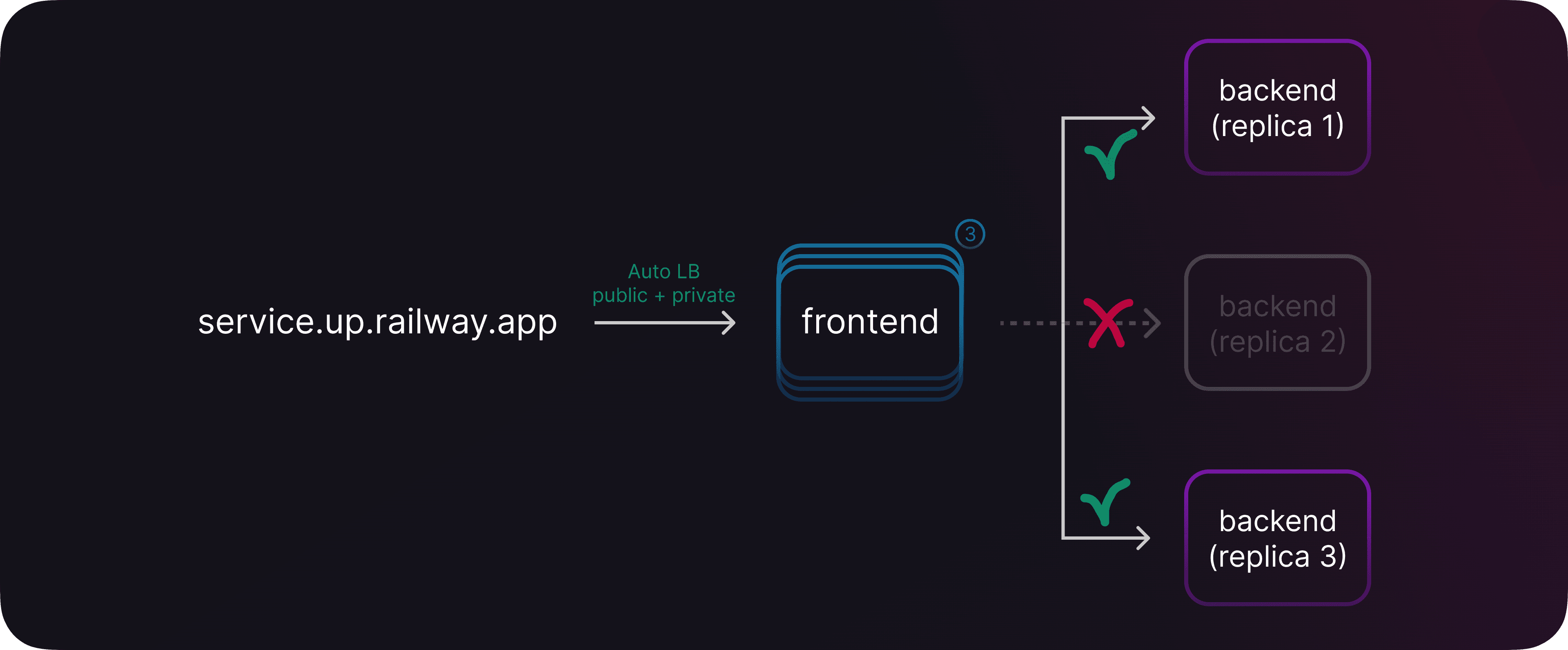
Network failover
The cherry on top is that your replicas are now spread across multiple machines in our fleet. So in the unlikely event where one of our servers starts flashing red, your service won't even notice it.
It's like having multiple backup generators. The show must go on!
And Replicas isn’t only useful for networked services. It’s also a great feature for worker pools and out-of-the-box distributed computing frameworks like Temporal, Apache Spark, you name it …
You can now leverage the power of Replicas to tackle complex distributed tasks or process large datasets with ease, enabling efficient and parallel processing.
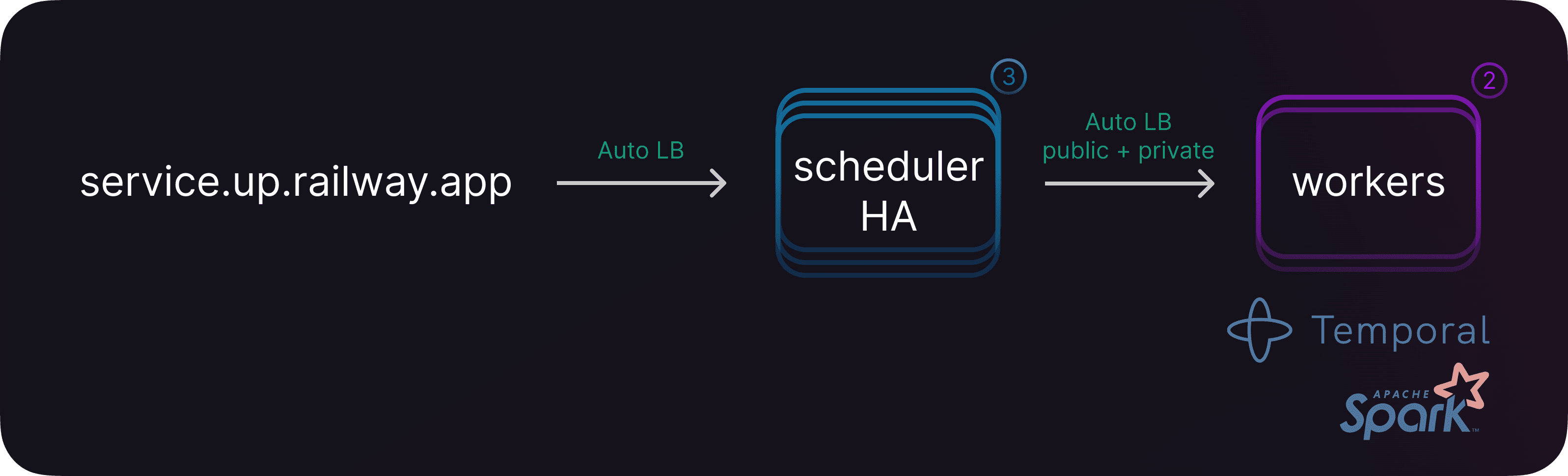
Horizontal Scaling unlocks parallel processing, too
So we shoved all these benefits into a single dial ... and while it might look simple on the surface, there’s a lot going on behind the scenes.
Wanna know how this all works?
Well, it’s a tale in two parts: orchestration and networking.
Let’s dig into the digital dirt and untangle the bits and bytes that make this scaling magic happen.
Let’s follow the journey of one of your deployments with replicas.
Before Replicas was a thing, our internal data model only accounted for one deployment of a service. So the first thing we did was to extend this to the notion of a deployment instance. A deployment instance captures all the same ingredients (your service settings, variables, environment, and more) and makes it repeatable.
One service, many deployment instances. Now let’s see how we use this new concept.
As we already mentioned, we love Temporal at Railway because it makes managing complex asynchronous workflows easy. Our internal, non-Kubernetes orchestrator is built on top of it. And since we use it for everything already, from billing to shipping your deployments on our fleet of stackers, it was only natural to use it for horizontal scaling, too.
The first thing that happens when you push code to your GitHub repo or when using our CLI railway up command is a Temporal workflow gets triggered to build your Docker image. Once the image is built and published to one of our registries (did we mention we rolled out our own now?), it’s time to deploy it.
A new temporal workflow starts, which takes care of a few concerns:
- Where should the new containers be deployed? In which region? What is the optimal stacker that offers the functionalities your deployment needs?
- How many of them should be shipped?
To start the deployment of the replica containers on the selected stackers, we then trigger sub-workflows. These are basically multiple copies of the same one we had in place before introducing replicas.
Then we use your healthcheck endpoints to determine when all the replicas are deployed and ready to rock.
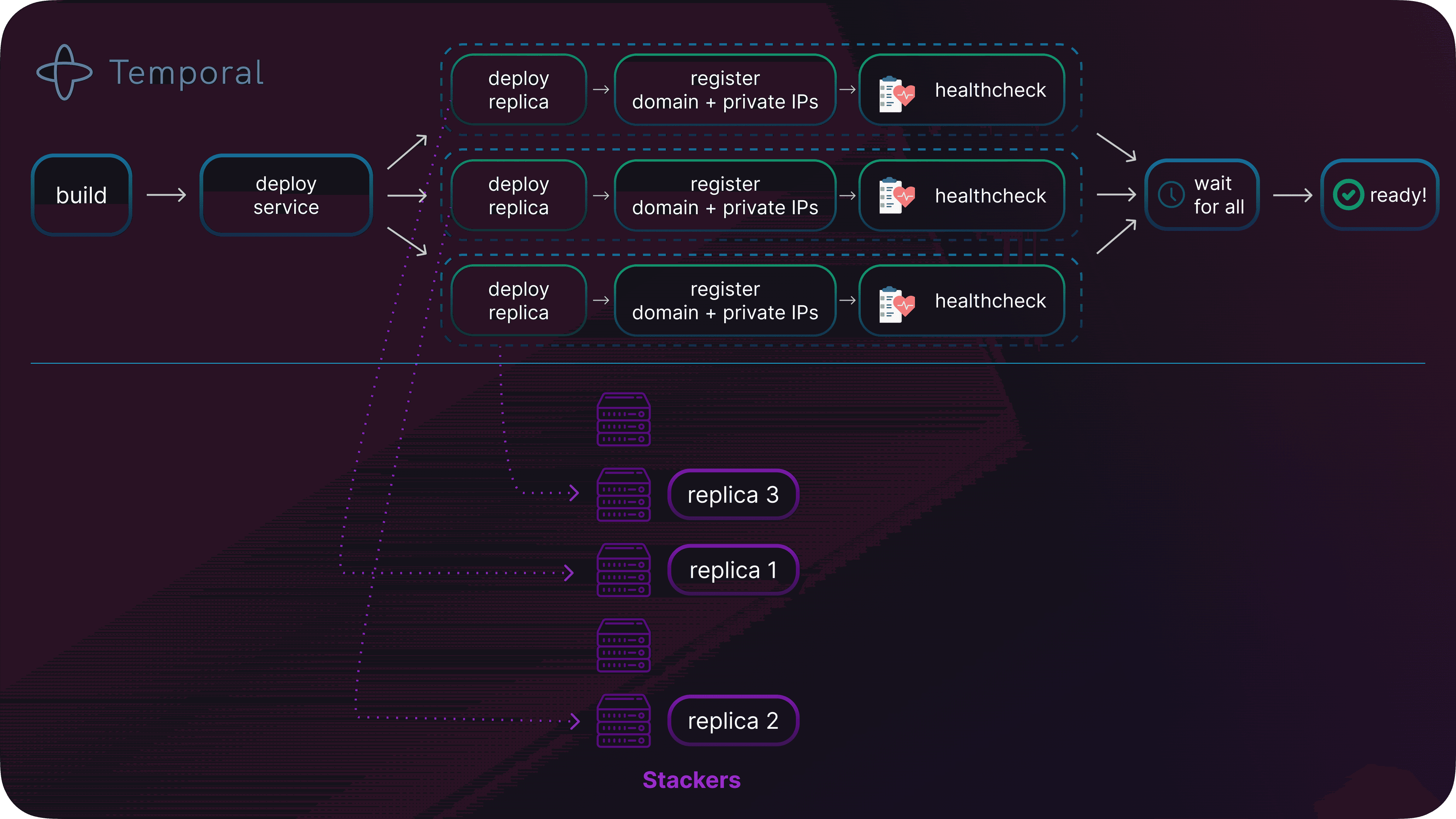
Orchestrating replicas deployment with Temporal
We’ve just covered how your replicas are being scheduled and deployed. But how exactly do your services chit-chat with each other?
Let’s see how we handle the distributed communication lines.
Over the private network, each of your services has a private DNS name.
Under the hood, when our orchestrator provisions a new container, we assign it a unique IPv6 address and push this address to our network control plane.
The network control plane is event based — the new update gets propagated to all listening proxies and DNS servers within milliseconds over gRPC.
When you re-query your Private Network DNS, we now have that new AAAA record right there ready for you. So when ServiceA talks to another Service B over the private network, it does so over a randomly picked IPv6 registered for ServiceB.
That’s how we ensure each replica gets its fair share of work.
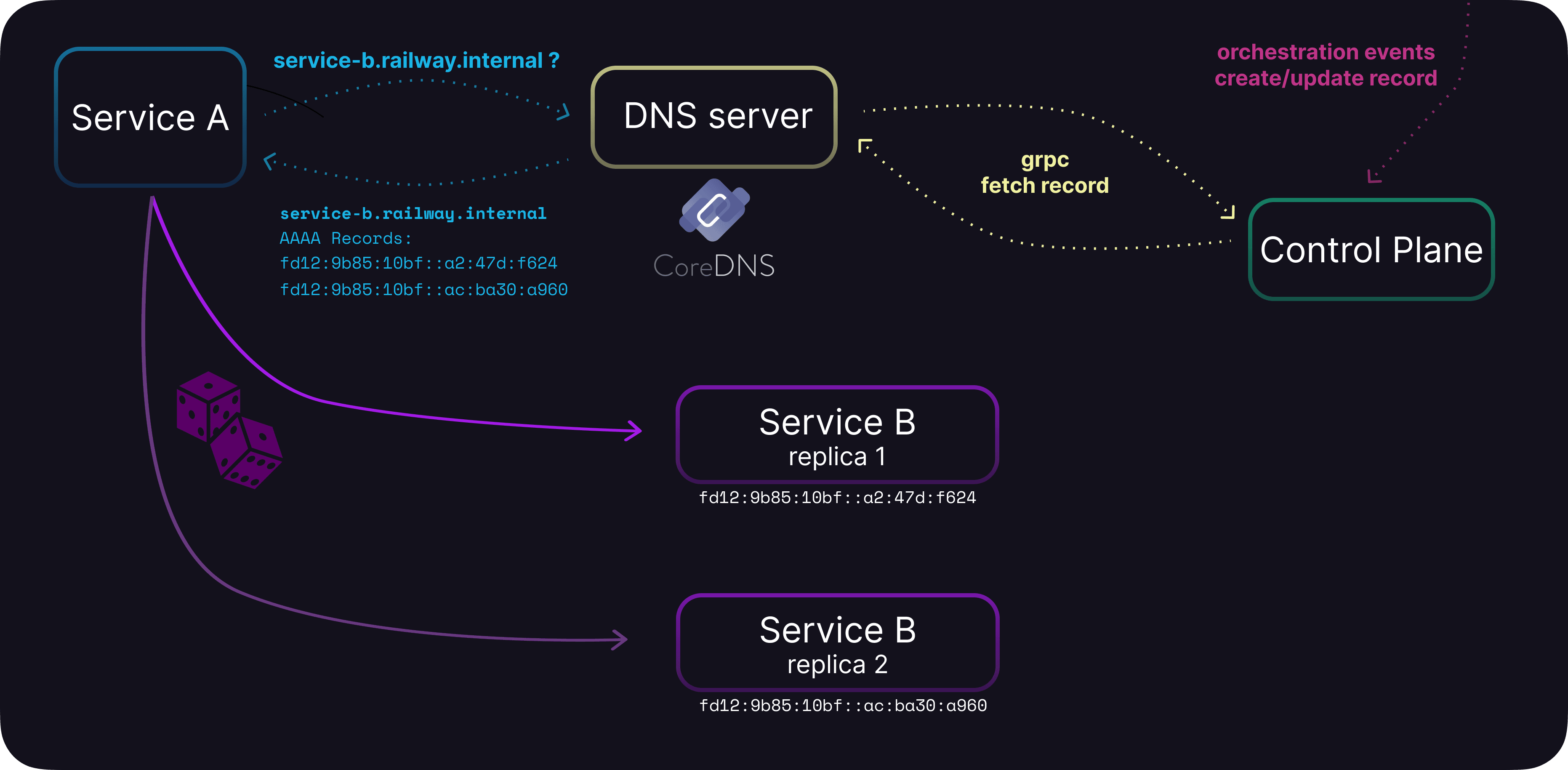
Networking architecture for Replicas
One important note: If you don’t like this random load balancing, you can stick your own NGINX/HAProxy middle-proxy (using our DNS to discover backends) and load balance with any algorithm you like.
For public networking, we use round-robin to load balance the requests.
Behind the scenes, ingress traffic into Railway is handled by our edge network — a fleet of Envoy proxies and a custom Go control plane.
This uses the same event-based architecture we use for private network endpoint updates: when a new replica gets provisioned, it will cause an Envoy CDS update which immediately injects the new replica into Envoy’s round-robin load balancing table.
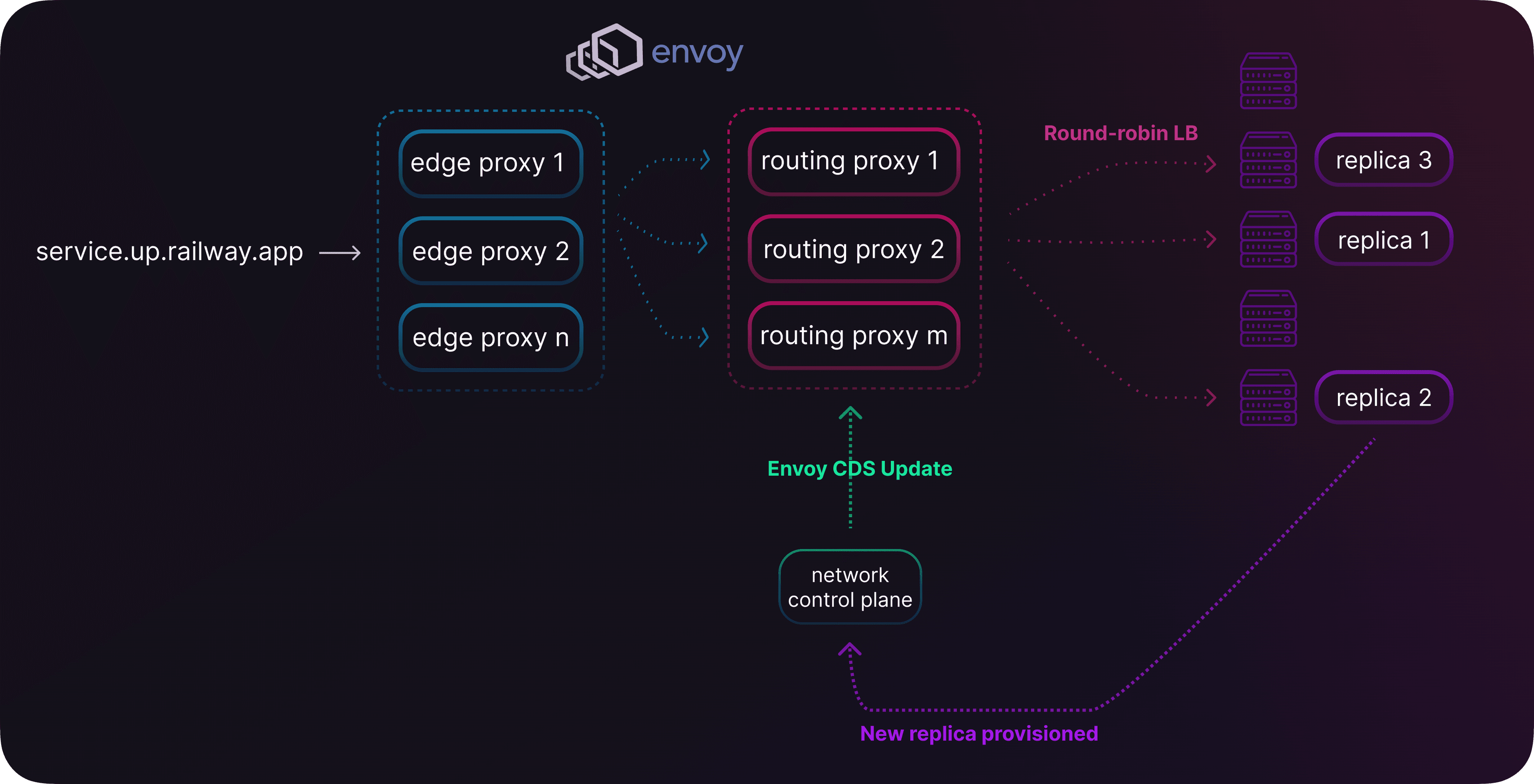
Envoy schema
These are admittedly pretty simple strategies, but we’re just getting started.
Your scenario might require more elaborate distribution schemes and we’re working on offering more balancing options in the future.
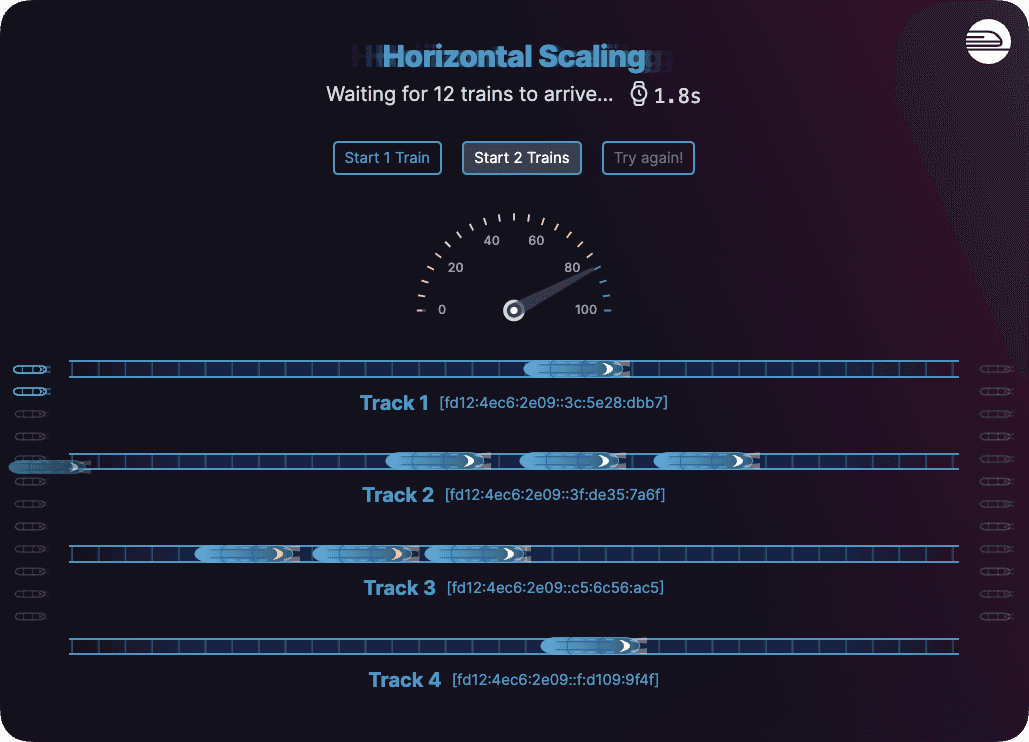
Be sure to check out our video demo from Launch Week to have some fun with trains. Here we see replicas depicted as tracks, each with their private ipv6. Trains are akin to workloads assigned to random replicas through load balancing.
You want to get into the fun part? Let’s get into the fun part.
Whenever we ship a new feature at Railway, we make it accessible to our users via our public GraphQL API.
To build autoscaling, we would start with reading the metrics API, then we can use another API endpoint to modify the replica count of a service.
The next logical step is a bit of code to tie these together.
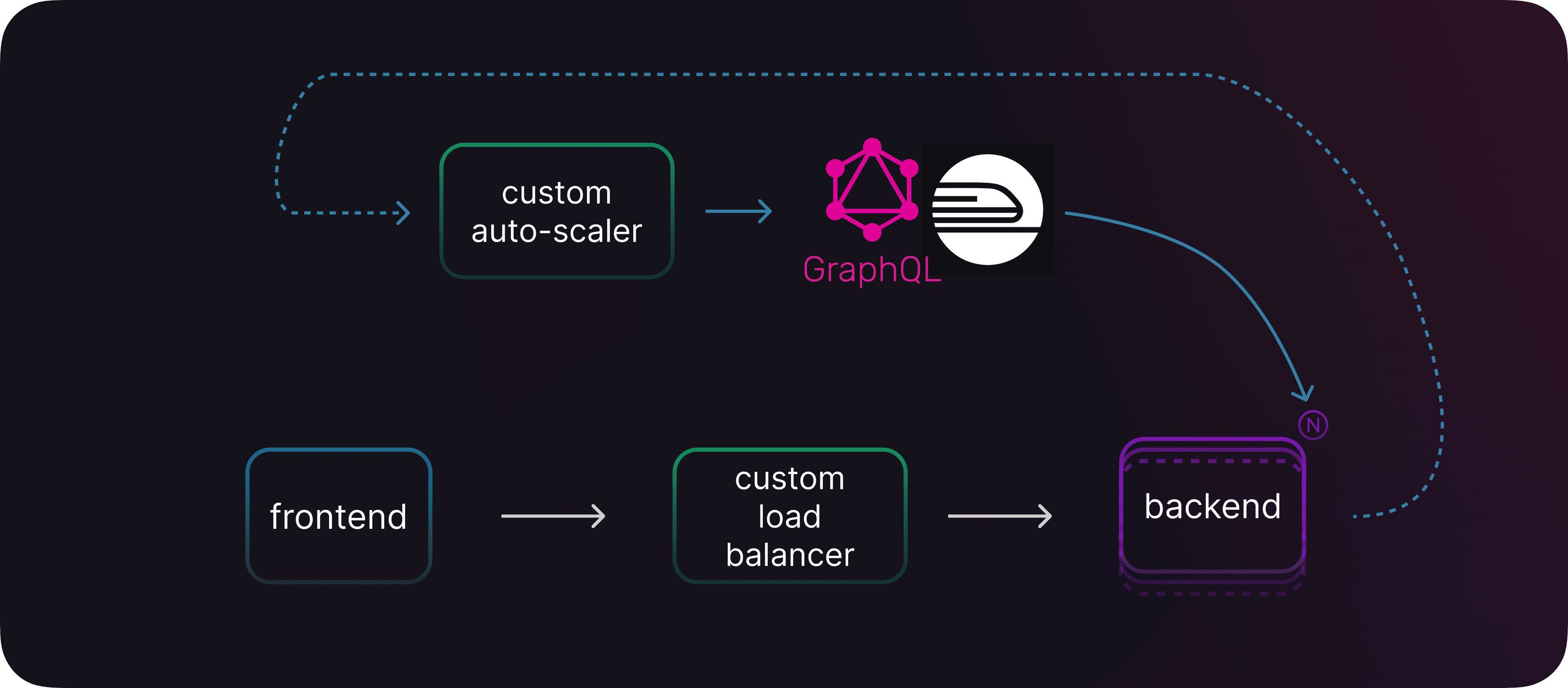
Autoscaling with the GraphQL api
Want to be a hero? Author your custom autoscaler as a Template and publish it. Your autoscaler is now one cmd+k away for anyone to integrate into their project. Now someone else can pull your genius down off the shelf and you can take the day off.
We’re hard at work on exposing more information and even more controls via these APIs. That will allow us to build more complex structures so you can build any logic you can think of into your custom autoscaler — think reacting to custom metrics thresholds, error logs, date and time, weather conditions … the rest is up to you!
Our philosophy in a nutshell is to build primitives, use them to build our own features, and then expose them to you so you can build things too!
Horizontal Scaling is but one of many primitives we’ve been building over the last quarter, along with Private Networking, Regions, Volumes, TCP proxying, and more. (If you’ve followed our launch week so far, you know that we also just launched 3 new regions on Railway.)
For now, your replicas are confined within a single region. But, we want to let them loose, with multi-region failover, to serve your users with the fastest available replica to them.
We’re also paving the way for built-in autoscaling, including the holy grail — Scaling to Zero! Soon your infrastructure will adjust itself automatically based on traffic and you won't even have to lift a finger.
Sound like a dream? Stay tuned, it's closer to reality than you think. 😉
Stay tuned for Day 04 of Launch Week when we’ll be introducing a new way to version your infrastructure!
Building the infrastructure which powers the Railway engine is the most core problem at Railway. Reach out if you’re interested in joining the team.
