 Miguel Casqueira
Miguel CasqueiraDo Apps Dream of Electric Sheep?
Welcome to Railway Launch Week 01. The theme of this week is Scale. Throughout the week we’ll be dropping some amazing new features to help your business and applications scale to millions of users.
If this is your first time hearing about us, we’re an infrastructure company that provides instant application deployments to developers.
Starting today in Priority Boarding, you can now automatically stop and start workloads with no traffic at the flip of a switch. This is what we’re calling Scale to Zero.
And here’s the real kicker — it works for databases too.
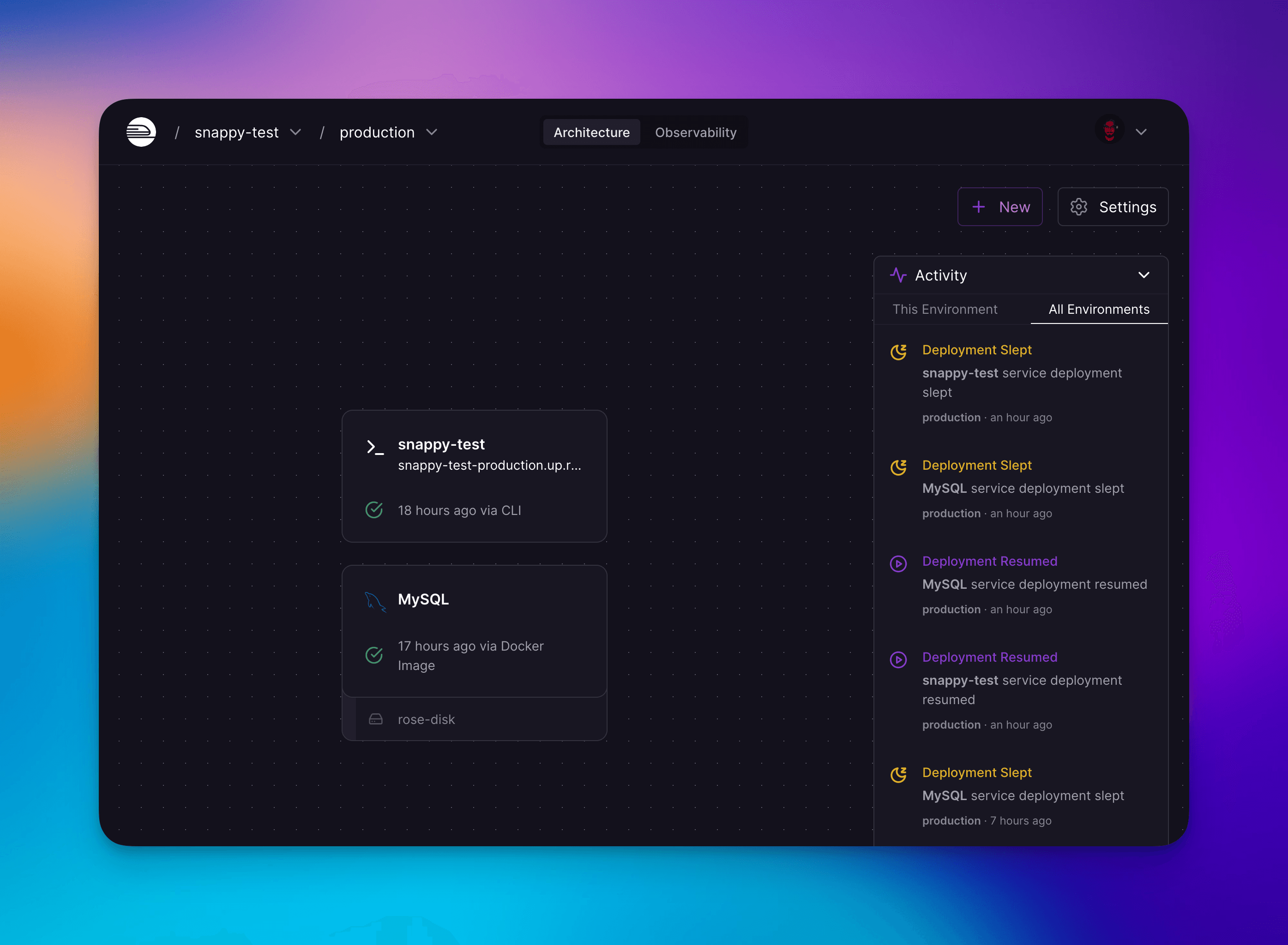
Application sleep events appear in the Activity view and work for all workloads
Idle resources represent untapped potential and unnecessary expenditure. Resources that are provisioned but not active are akin to leaving the lights on in an unoccupied room, continuously draining power (and in this case, your budget) without providing value in return.
That’s why we’ve enabled a new way to experiment with different projects without burning up your credits. Maybe you're trying out a new potential startup idea but are worried about unnecessary costs. Or maybe want an exact copy of your production environment to run some tests on but don’t need it again after.
We want you to feel like you can spin up infrastructure as easy as if you were developing in your local environment. This means it should be as simple as shutting your laptop screen to stop your side project's servers.
This is possible because Railway bundles up your application and finds it a home somewhere close to your users around the world. Since we control the network and machines running your app, we can build-out super powers for you, like automatically stopping your apps when there’s no traffic.
Let’s get into how this works.
The normal path for your traffic starts from the Internet and meets our edge network. The edge network leverages Envoy proxies to help direct connections to the correct box in our pool that has your application. And once the traffic is there ? That’s when container networking takes over, facilitated by namespaces and nftables (iptables).
Namespaces play a crucial role in achieving the isolation that makes containers efficient and secure. They enable containers to have their own instances of global system resources, allowing processes within the container to have their own private view of the system. Among these, network namespaces are pivotal, ensuring that each container has its own isolated network stack.
Nftables enter the fray when the processes within a container needs to communicate with the outside world. Nftables are linux kernel-based utilities that manages network packet filtering and NAT, playing a crucial role in determining how packets are forwarded between networks — including between host and containers.
When a packet reaches the host machine, it traverses through various tables (like filter and NAT tables) and chains (like INPUT, PREROUTING, FORWARD, and OUTPUT) in nftables. These tables and chains contain rules, and each rule specifies what to do with a packet that matches certain criteria. Our current containerization system leverages nftables to manipulate packet routing and manage port forwarding, ensuring that the incoming packets on a certain port are sent to the correct container.
For Scale to Zero we can also play a game of musical chairs.
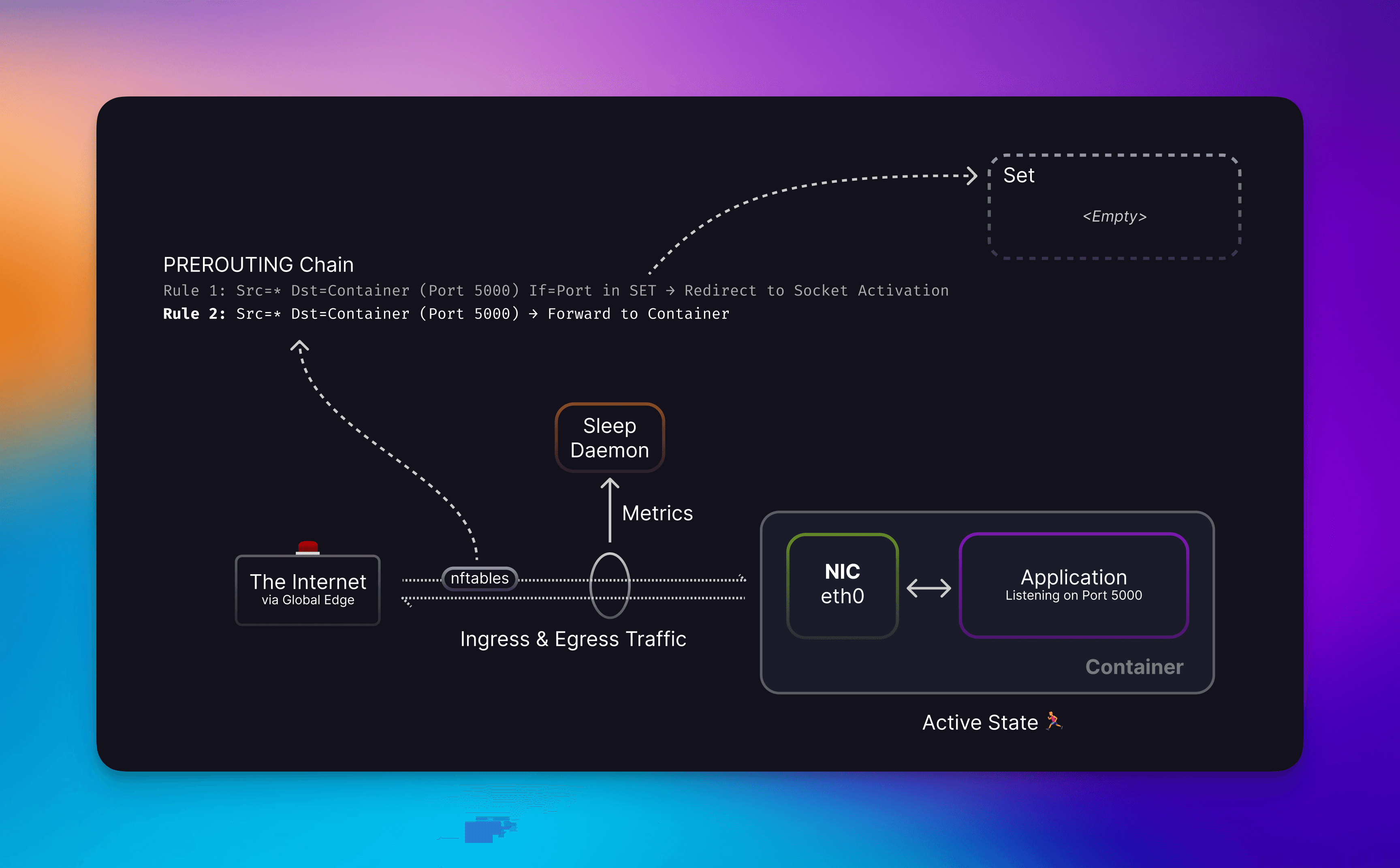
Traffic reaches your container on the eth0 interface via port forwarding rules on the host, skipping over the higher priority redirect rule because the port is not in the set.
Nftable rules are evaluated based on priority. If you have two rules that match but one is higher in the chain it will get the traffic. Leveraging this, we inject a rule on the same PREROUTING chain that containers are using to ensure we get the traffic. This isn’t to steal traffic from the container, because if it was up to us why would we want to interfere with that? The reason is to guarantee no downtime when handling the connections. This is because even though your container may be up and the kernel will forward traffic to your container, your application might not be ready yet.
We couldn’t just go and add tons of rules though because each one must be evaluated and this can impact the performance of kernel networking. So instead we added a rule that uses a Set. This allows for constant lookup O(1) instead of checking a list O(N) if a port has a rule.
With no ports in our set, traffic is quickly directed to your container. Beautiful!
As shown in the image above, we included a sleep daemon to collect metrics on ingess/egress traffic. This daemon leverages cAdvisor which powers our Metrics feature. Every 5 minutes it compares outbound packets and once no new packets have been sent, the container is flagged as inactive. We opted for 5 minute intervals because this produces a 5-10 minute window to stop an inactive container since cAdvisor has its own collection interval.
We opted for outbound traffic since the internet is a scary place. If you have something on the internet, it will be scanned. Therefore, we didn’t want random external code that isn’t actually triggering work on the application to keep it up at night.
Although this does have the downside of being broken for workloads where traffic is only received and doesn’t leave, I’d love to talk to you about this type of workload because what the heck is it, a black hole?
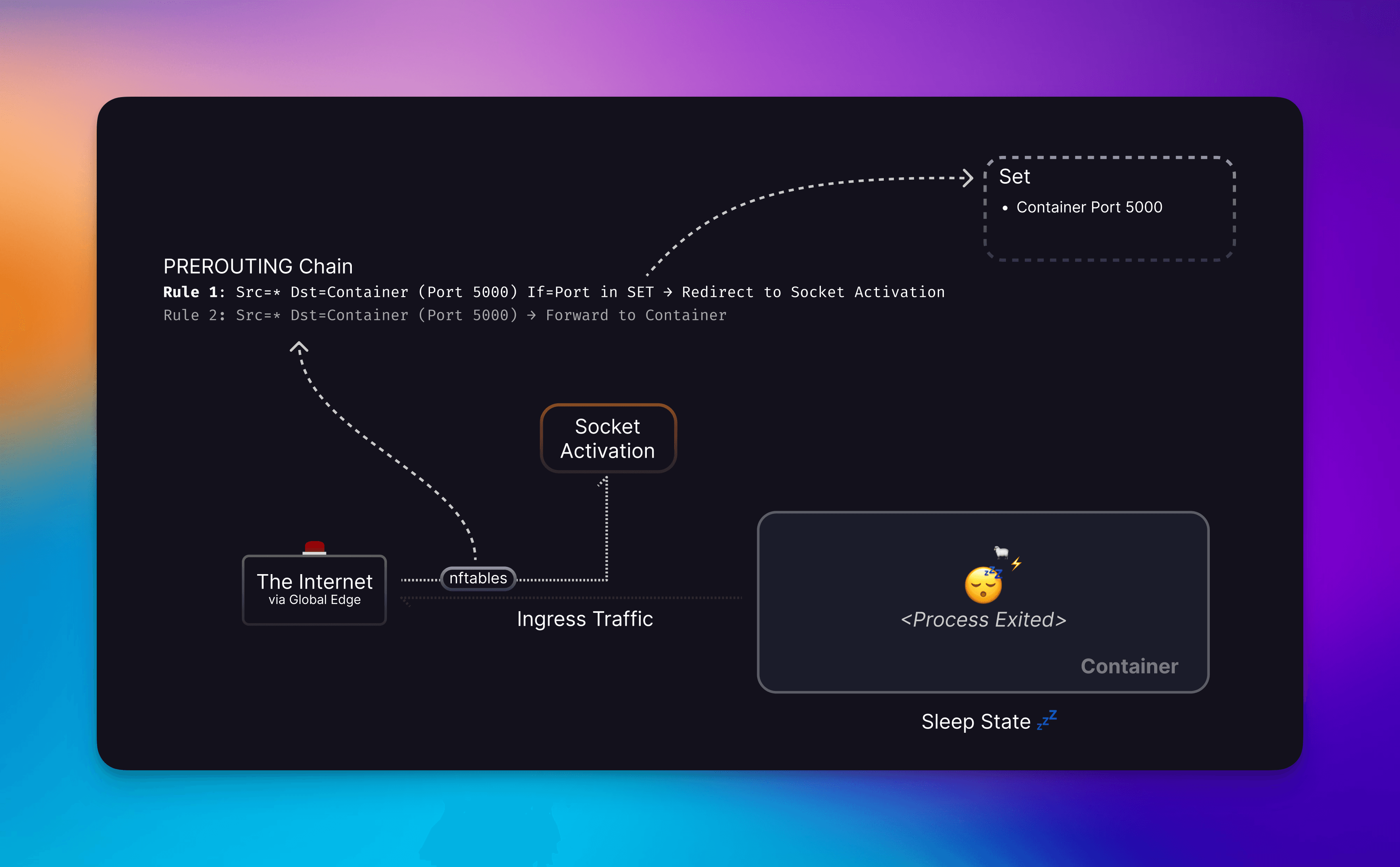
A container dreaming, possibly of electric sheep.
Once we consider a container as inactive , we’ll stop the container (instead of removing it) so that whatever you wrote to a disk but not a volume remains. (Note: You should be persisting important bits to Volumes not container layers!) The container’s port is then added to our redirect Set and whenever Ingress traffic comes in from the edge, we’ll be able to redirect that to the Socket Activation service.
Let’s dive a bit deeper into how exactly we handle your traffic when the container is not running. There are plenty of protocols for communicating on the internet and since we want you to be able to run anything on Railway, this meant we couldn’t just awake on L7 traffic.
What we’ve built is a L4 socket activation server. When your container is flagged as inactive, we add your container’s port to the redirect set which causes TCP traffic destined for your container’s port to be sent to the socket activation server. When the connection is handled, we’ll read the SO_ORIGINAL_DST socket option set when a connection has been redirected by nftables to get the original port. This allows us to find your stopped container and start it.
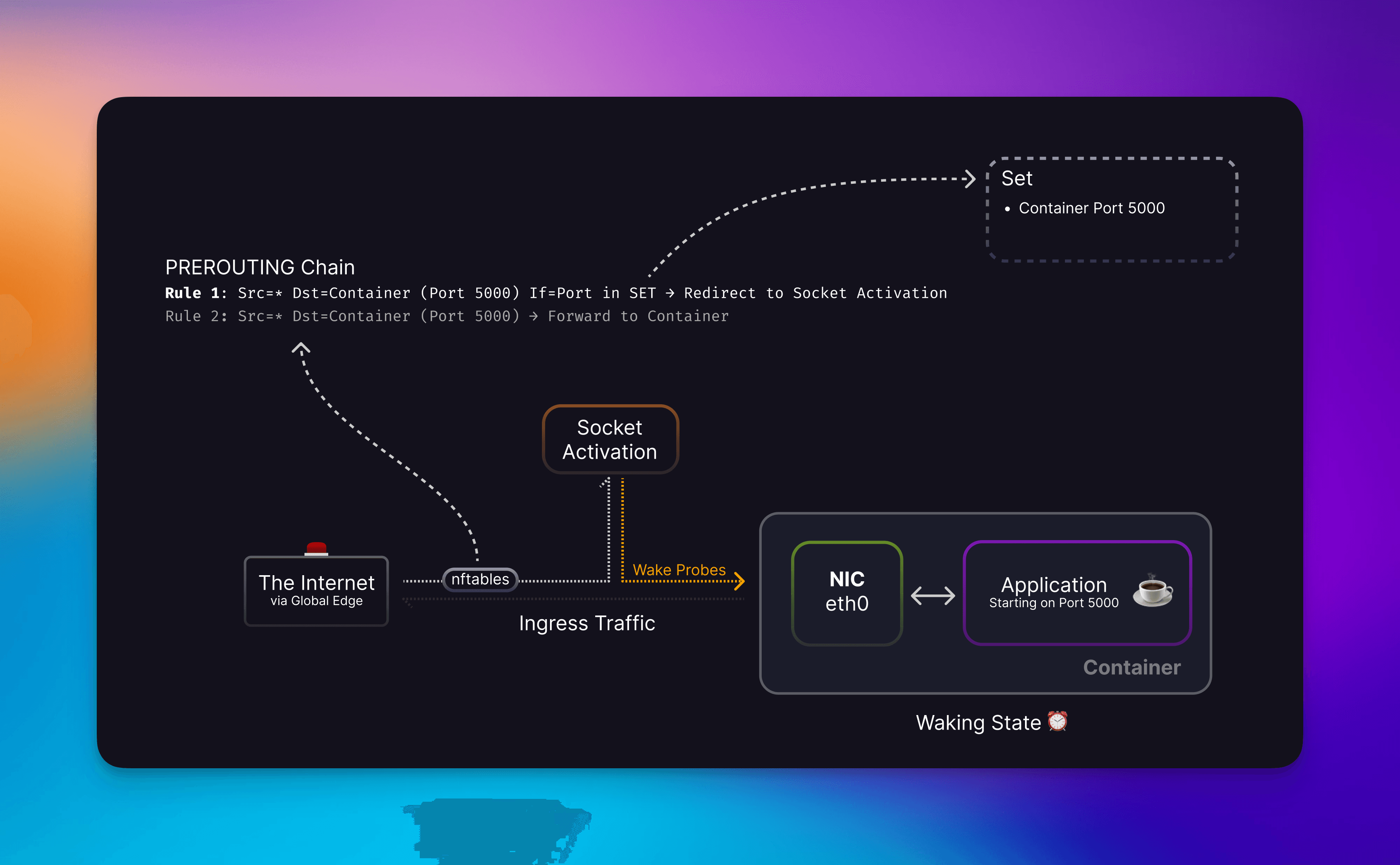
Socket Activation process receiving redirected container traffic and trying to start said container
Since the process within your container may take some time to start, we cannot begin to forward traffic yet. So we implement a probing function to see if a TCP server is active in your application. We attempt this probe in 30 ms intervals up to a total of 10 seconds.
Now with the container ready, we bidirectionally forward the bytes from the client to the container. During this time, any number of connections can be accepted and forwarded as soon as the container is ready.
Note: We want connections being as direct as possible. After 30 minutes of traffic the TCP connection will be closed so they communicate directly with the container. This only affects the connections which got accepted during the container awake event.
When we detect that we’re able to send traffic to your app, we’ll remove it from our nftable set to allow traffic from our load balancer to go directly to your container. This means that we never drop any connections while starting your container!
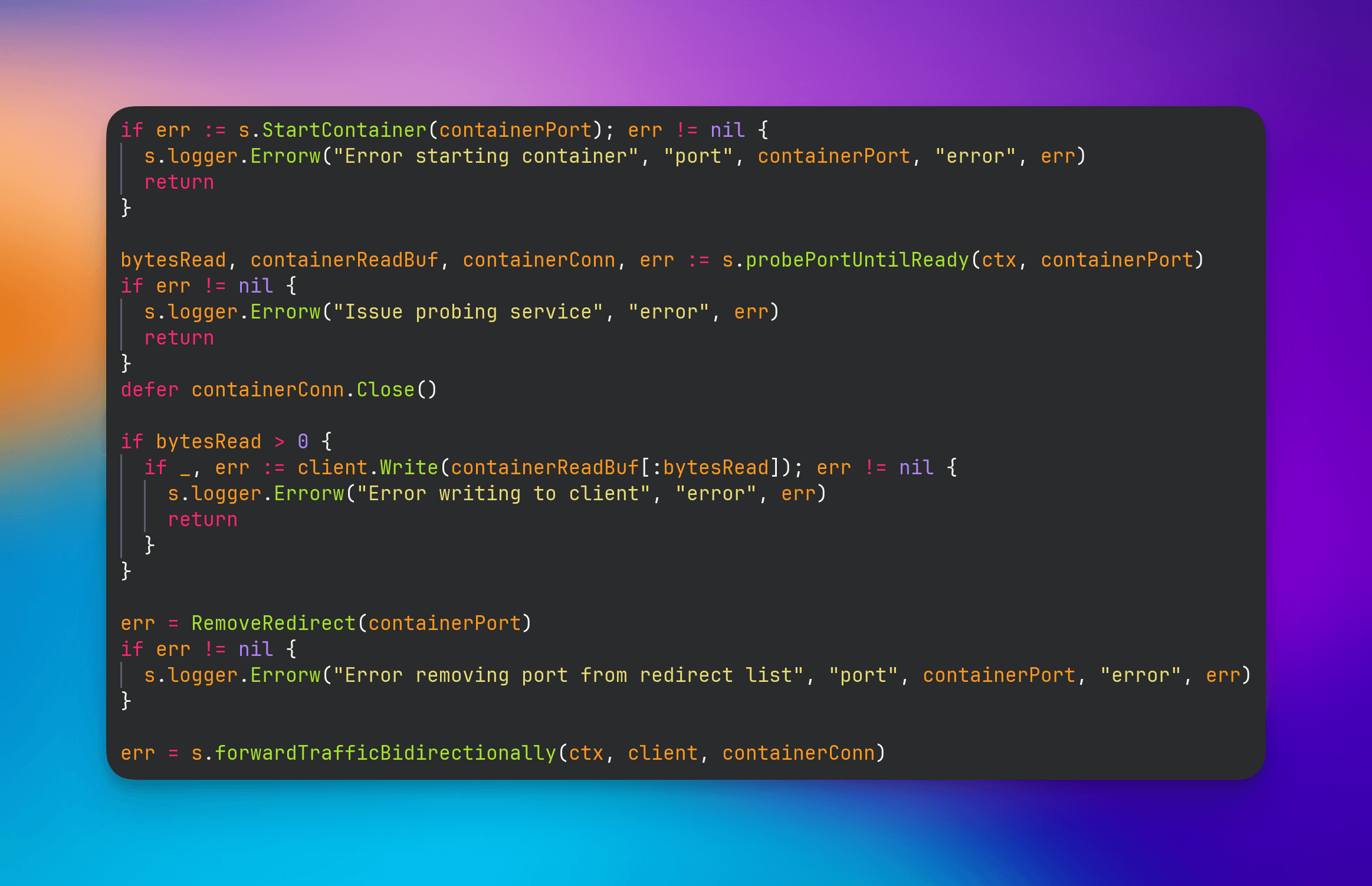
Our version of musical chairs. Start container, probe til ready, remove redirect, forward traffic.
Why did we implement this in L4 instead of just L7 since you might assume the internet is mostly HTTP ? By us supporting a more ubiquitous protocol we can allow for more diverse workloads. As a result, we can now offer serverless Redis, Postgres, ClickHouse, etc… it’s all TCP so it will just work!
Did you make a cron job to perform some kind of backup but want the database of your choice to also be slept when you’re done ? No problem! None of your clients have to be aware any of this is happening.
The biggest concern with stopping an application is what happens when a request arrives at the front door. While the client will notice a few hundred ms of latency, nothing else is required for it to work.
When we built this solution, we knew that it had to have low latency because we care about your experience and your users’ experience on the platform. To give you an idea of latency, we consistently observe < 1 second to get a complete HTTP response with a few hundred bytes of data on cold boot.
The best part about this is that over time, as we iterate on what we have now, we can decrease the start times for you automatically by running your app in lightweight containers, optimizing and cacheing your source code, and leveraging KVM and memory snapshots.
If you’re a Priority Boarding user you’ll be able to use this feature now! Simply go to your service → settings and toggle Enable App Sleeping.
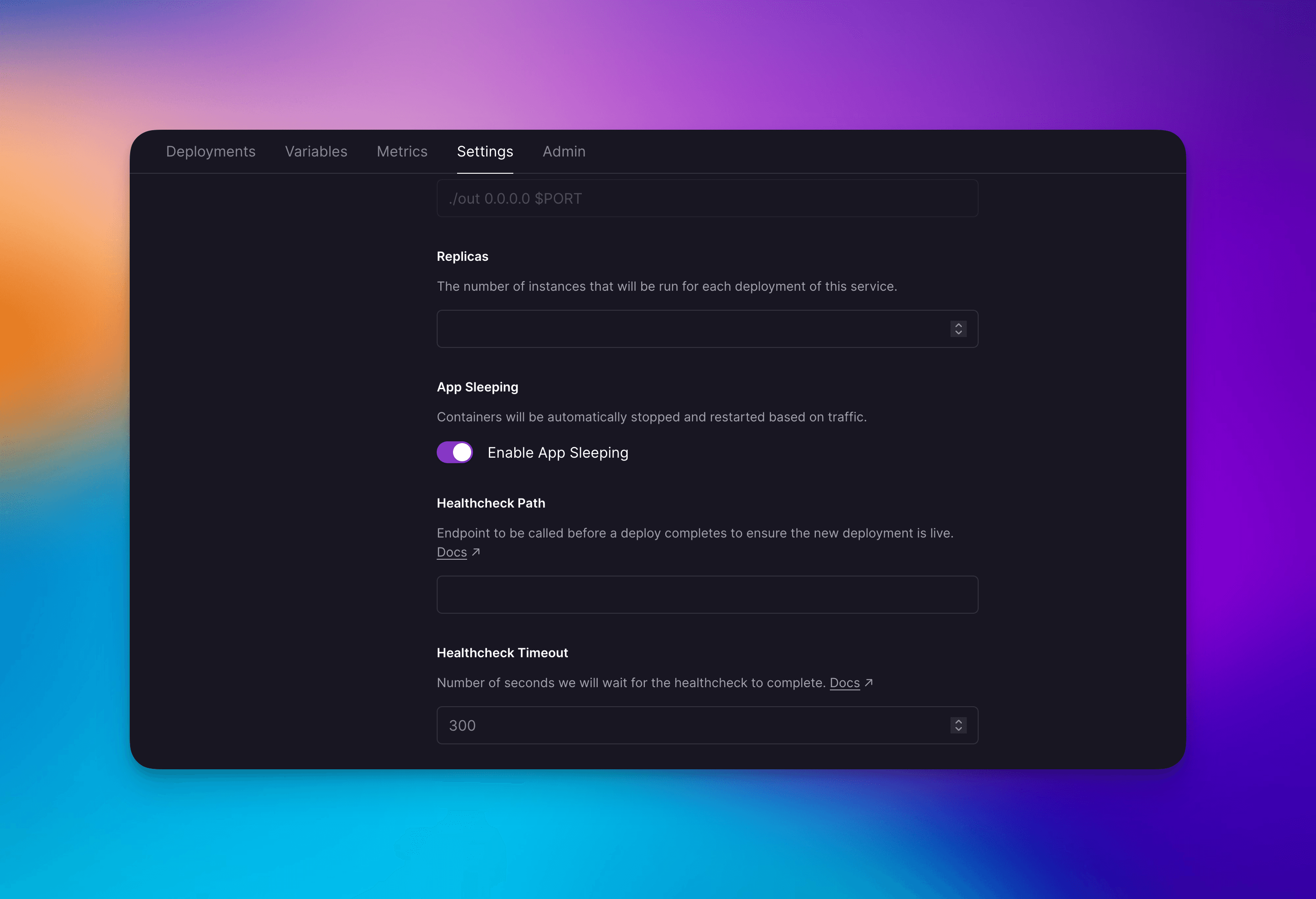
The App Sleeping toggle can be found in the Service’s Settings view
If you have any replicas this setting will apply for all of them automatically.
After a few minutes (we aim for 10), if your container has no traffic it will be slept and you’ll see an event in the dashboard.
Note: If you notice your service not being slept, go to the metrics view and see if there’s any outbound traffic in the last 10 minutes.
When you want to disable App Sleeping just toggle the setting again.
We’d like for toggling application sleep not to trigger a redeploy. We do plan to have a way not to trigger deploys for a few different settings, not just this one… yet. Thankfully the builds are all cached so the subsequent deploy is super fast.
Closing the connection after 30 minutes of even active use isn’t a great UX. We should be able to get away with passing on the connection to the container via SOCKMAP.
We’d also like to support UDP, but this is something we’d have to support for the whole platform to unlock things like game servers and video/audio streaming protocols that aren’t on TCP. In fact, HTTP/3 is UDP which is something we’d love to see supported all the way from the browser to your container so you can manage terminating TLS yourself if you’d like to. Once the platform supports UDP we’ll definitely jump at the chance to offer socket activation for those workloads.
We also want to look at resource vs network-based sleeping. Since the sleep algorithm is just tracking outbound traffic, when you have replicas which get traffic evenly due to the round robin routing, it only takes four requests to spin up all four of your replicas. With a resource-based approach we can stop and start containers when your replica is under/over utilized. We think this feature will still greatly benefit a lot of users since they don’t run replicas in staging or for smaller projects.
Ship fast and get feedback early
So, that’s Scale to Zero. Your application, or database, or anything that speaks TCP, can now scale all the way up to 11, or all the way down to 0.
We do want to say that this isn’t a silver bullet. It’s more like an extra 1-Up in your toolkit. For non-hobby, production usecases, we’d actually always recommend having an instance “Hot N Ready.” At least for us, it doesn’t really matter how quick we can get the coldstarts, as there will always be a variance/overhead, and that’s not acceptable to our customers or for our internal telemetry (as the jitter will leak over into traces/timing/etc).
That said, this feature has a wealth of use-cases for all users ranging from Indiehackers to F500 companies.
Indiehackers can save their hard-earned dollars by automatically turning the lights on until their “big break on Hacker News.” When that comes, they can flip a single switch and let us handle the scaling while they handle the guy who is adamant he “could have built this in a weekend.”
For our Fortune 500 customers, they won’t have to nag their amazing engineers by asking them if they “turned off the PR environment for the evening/weekend/etc.” It’ll just happen automatically.
Regardless of which way you slice it, this feature lets you do more with less. That’s one of our core missions at Railway and that’s why we’re so excited to share this feature with you.
We hope you enjoyed Launch Week 01! To see everything we shipped this week check out the Launch Week landing page.
